本文的内容主要分为两部分:
- NodeJS 的基础和架构
- NodeJS 核心模块的实现
NodeJS 的基础和架构
一、NodeJS 的组成
Node.js 主要由 V8、Libuv 和第三方库组成。
1、Libuv
Libuv 是 Node.js 底层的异步 IO 库,但它提供的功能不仅仅是 IO,还包括进程、线程、信号、定时器、进程间通信等,而且 Libuv 抹平了各个操作系统之间的差异。Libuv 提供的功能大概如下:
- Full-featured event loop backed by epoll, kqueue, IOCP, event ports.
- Asynchronous TCP and UDP sockets
- Asynchronous DNS resolution
- Asynchronous file and file system operations
- File system events
- ANSI escape code controlled TTY
- IPC with socket sharing, using Unix domain sockets or named pipes (Windows)
- Child processes
- Thread pool
- Signal handling
- High resolution clock
- Threading and synchronization primitives
2、V8
Node.js 是基于 V8 的 JS 运行时,它利用 V8 提供的能力,极大地拓展了 JS 的能力。这种拓展不是为 JS 增加了新的语言特性,而是拓展了功能模块,比如在前端,我们可以使用 Date 这个函数,但是我们不能使用 TCP 这个函数,因为 JS 中并没有内置这个函数。而在 Node.js 中,我们可以使用 TCP,这就是 Node.js 做的事情,让用户可以使用 JS 中本来不存在的功能,比如文件、网络。Node.js 中最核心的部分是 Libuv 和 V8,V8 不仅负责执行 JS,还支持自定义的拓展,实现了 JS 调用 C++ 和 C++ 调用 JS 的能力。比如我们可以写一个 C++ 模块,然后在 JS 调用,Node.js 正是利用了这个能力,完成了功能的拓展。JS 层调用的所有 C、C++ 模块都是通过 V8 来完成的。可以说得益于 V8 支持自定义扩展这才有了 Node.js
3、第三方库
Node.js 中的第三方库主要包括异步 DNS 解析( cares )、HTTP 解析器(旧版使用 http_parser,新版使用 llhttp)、HTTP2 解析器( nghttp2 )、 解压压缩库( zlib )、加密解密库( openssl )等等。
二、NodeJS 代码架构
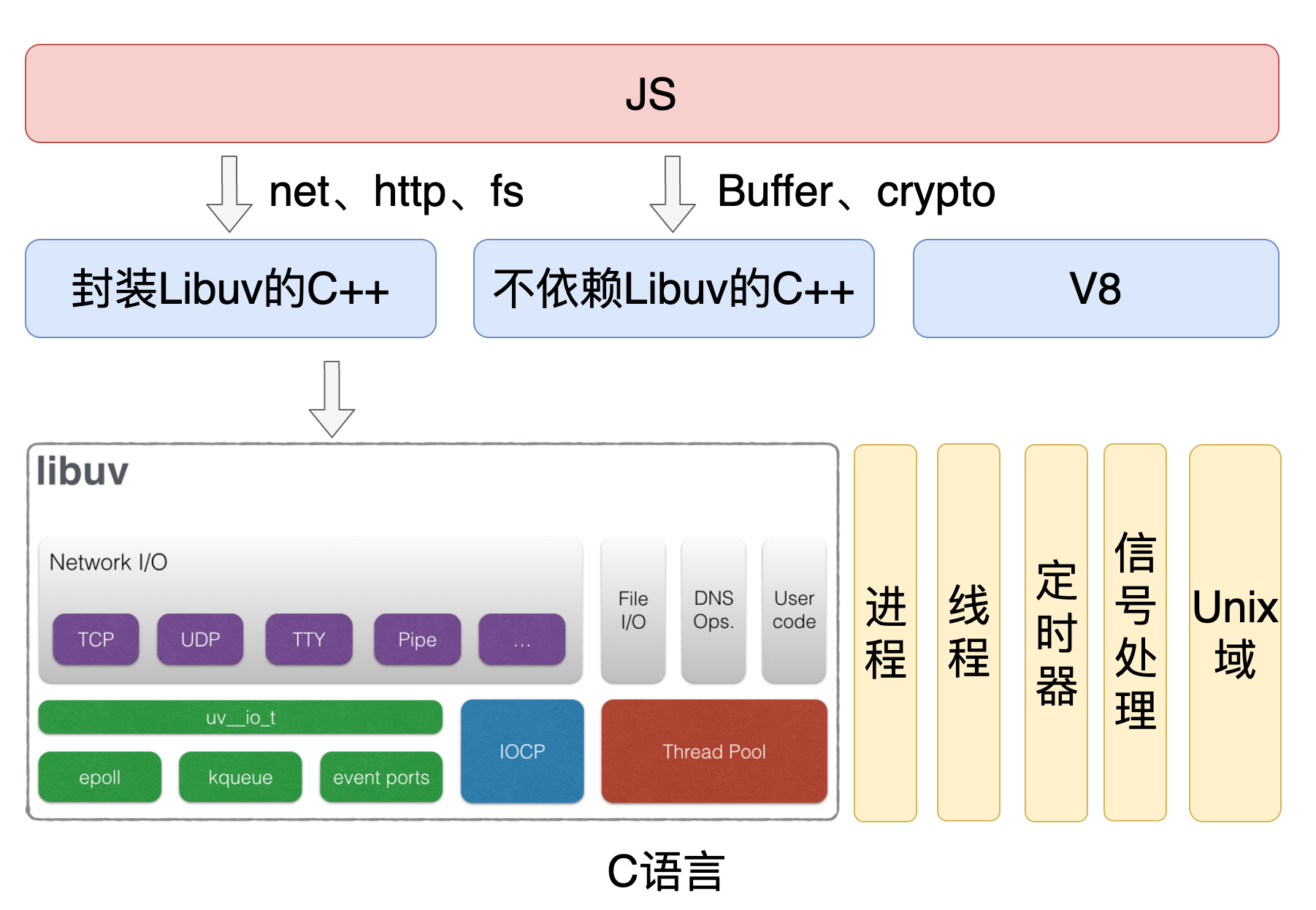
上图是 Node.js 的代码架构,Node.js的代码主要分为 JS、C++、C 三种。
- JS 是我们平时使用的那些模块(http/fs)。
- C++ 代码分为三个部分,第一部分是封装了 Libuv 的功能,第二部分则是不依赖于 Libuv ( crypto 部分 API 使用了 Libuv 线程池),比如 Buffer 模块,第三部分是 V8 的代码。
- C 语言层的代码主要是封装了操作系统的功能,比如 TCP、UDP。
了解了 Node.js 的组成和代码架构后,我们看看 Node.js 启动的过程都做了什么。
三、NodeJS 启动过程
Node.js启动的主流程图如下所示:
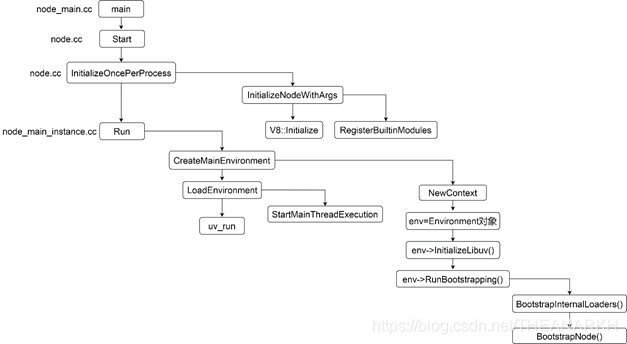
涉及到的文件也包括
- src/node_main.cc
- src/node.cc
- src/env.cc
- lib/internal/bootstrap/loader.js
- lib/internal/bootstrap/node.js
接下来我们详细分析每个过程:
1、启动
node 的启动函数在 src/node_main.cc 文件当中,这个文件主要是根据操作系统的不同运行了对应的变量设置。然后会调用 node.cc 中的 __Start()__ 函数。node.cc 中有三个 Start 函数现在我们依次来看看,
1、注册 C++ 模块

首先 Node.js 会调用 RegisterBuiltinModules 函数注册 C++ 模块,这个函数会调用一系列 registerxxx 的函数,我们发现在 Node.js 源码里找不到这些函数,因为这些函数是在各个 C++ 模块中,通过宏定义实现的,宏展开后就是上图黄色框的内容,每个 registerxxx 函数的作用就是往 C++ 模块的链表了插入一个节点,最后会形成一个链表。
这儿我们以 _register_tcp_wrap 函数为例详细分析一下在函数中具体做了什么,在这之前我们要先了解一下 Node.js 中表示 C++ 模块的数据结构:
1 | struct node_module { |
_register_tcp_wrap 函数调了 node_module_register,并传入一个node_module数据结构,这里我们看一下 node_module_register 的实现:
1 | void node_module_register(void* m) { |
C++ 内置模块的 flag 是 NM_F_INTERNAL,所以会执行第一个 if 的逻辑,modlist_internal 类似一个头指针。if 里的逻辑就是头插法建立一个单链表。
那么 Node.js 里是如何访问这些 C++ 模块的呢?在 Node.js 中,是通过 internalBinding 访问 C++ 模块的,internalBinding 的逻辑很简单,就是根据模块名从模块队列中找到对应模块。但是这个函数只能在 Node.js 内部使用,不能在用户 JS 模块使用,用户可以通过 process.binding 访问 C++ 模块。
2、创建 Environment 对象,并绑定到 Context
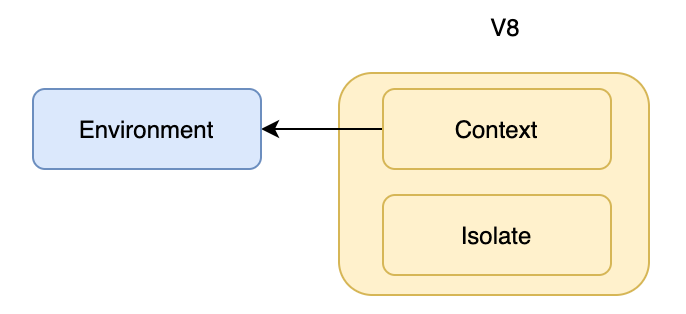
注册完 C++ 模块后就开始创建 Environment 对象,Environment 是 Node.js 执行时的环境对象,类似一个全局变量的作用,他记录了 Node.js 在运行时的一些公共数据。创建完 Environment 后,Node.js
会把该对象绑定到 V8 的 Context 中,为什么要这样做呢?
主要是为了在 V8 的执行上下文里拿到 env 对象,因为 V8 中只有 Isolate、Context 这些对象,Isolate用于隔离实例间的环境,Context用于提供JS执行时的上下文,如果我们想在 V8 的执行环境中获取 Environment 对象的内容,就可以通过 Context 获取 Environment 对象。
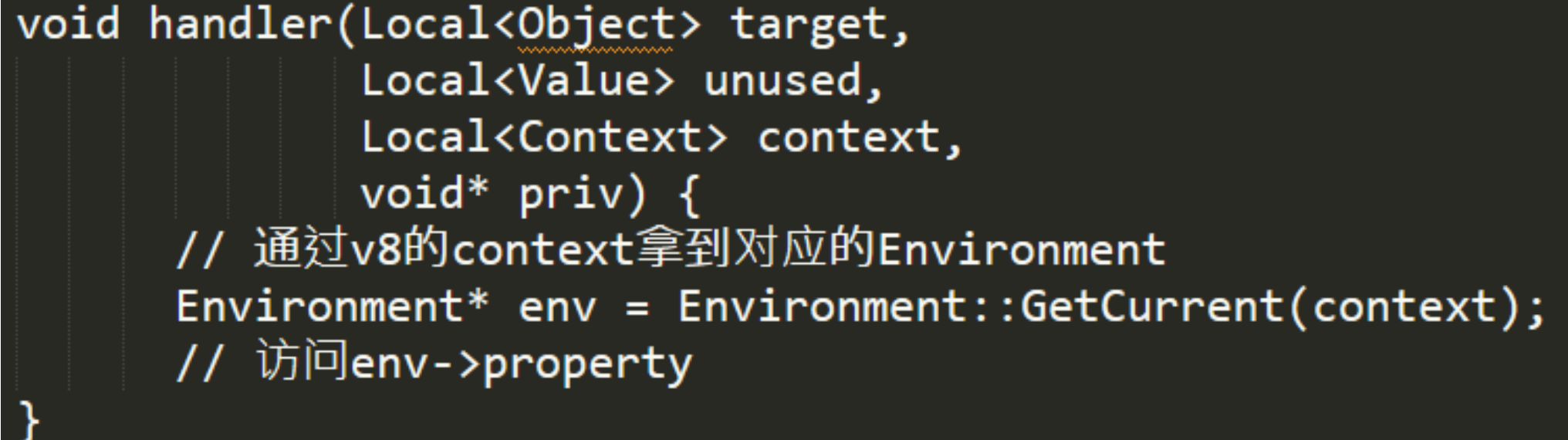
实际上这一步骤 Node.js 主要做了如下4件工作:
- 进入当前 Context
- 保存环境变量
- 关联 context 和 env
- 创建其他对象
具体实现如下:
1 | Environment::Environment(IsolateData* isolate_data, |
这里的 CreateProperties 主要是用于创建诸如 process 等对象,创建之后也会保存到 Environment 对象中。
3、初始化 Libuv 任务
InitializeLibuv 函数中的逻辑是往 Libuv 中提交任务,在 InitializeLibuv 函数中会调用 uv_idle_init、uv_prepare_init、uv_async_init 等 Libuv 提供的方法向 Libuv 不同阶段插入任务节点:
1 | void Environment::InitializeLibuv(bool start_profiler_idle_notifier) { |
- timer_handle 是实现 Node.js 中定时器的数据结构,对应 Libuv 的 time 阶段
- immediate_check_handle 是实现 Node.js 中setImmediate的数据结构,对应Libuv的check阶段
- task_queues_async_用于子线程和主线程通信
- 。。。
3、初始化模块加载器和执行上下文
RunBootstrapping 里调用了 BootstrapInternalLoaders 和 BootstrapNode 函数,我们一个个进行分析
初始化loader
BootstrapInternalLoaders 用于执行 internal/bootstrap/loaders.js,对应的逻辑转成 JS 如下所示:
1 | function demo(process, getLinkedBinding, getInternalBinding, primordials) { |
V8 把 internal/bootstrap/loaders.js 用一个函数包裹起来,参数是 process, getLinkedBinding, getInternalBinding, primordials,而其将会导出一个对象。这儿我们先看一下 getLinkedBinding, getInternalBinding 这两个函数,Node.js 在 C++ 层对外暴露了 AddLinkedBinding 方法注册模块,Node.js 针对这种类型的模块,维护了一个单独的链表。getLinkedBinding 就是根据模块名从这个链表中找到对应的模块。而对于对于 C++ 内置模块,Node.js 同样维护了一个链表,getInternalBinding 就是根据模块名从这个链表中找到对应的模块。
而执行完 internal/bootstrap/loaders.js 将会返回三个变量给 C++ 层:
1 | return { |
其中 internalBinding 的生成方法如下:
1 | let internalBinding; |
在这儿 Node.js 在 JS 对 getInternalBinding 进行了一个封装,主要是加了缓存处理。
然后我们再看 NativeModule,Node.js 中除了 C++ 模块还有原生 JS 模块,对于加载原生 JS 模块的处理。Node.js 专门定义了一个 NativeModule 类负责原生 JS 模块的加载,还定义了一个变量保存了原生JS模块的名称列表:
1 | static map = new Map(moduleIds.map((id) => [id, new NativeModule(id)])); |
NativeModule主要的逻辑如下
- 原生 JS 模块的代码是转成字符存在 node_javascript.cc 文件的,NativeModule 负责原生 JS 模块的加载,即编译和执行。
- 提供一个 require 函数,加载原生 JS 模块,对于文件路径以 internal 开头的模块,是不能被用户 require 使用的。
而这些原生 JS 模块内部往往还需要调用 C++ 模块进行处理,因此 internal/bootstrap/loaders.js 中还封装了 process.binding 方法来方便 JS 层根据模块名查找对应的 C++ 模块,其具体的实现方法如下:
1 | const internalBindingWhitelist = new SafeSet([, |
internal/bootstrap/loaders.js 在返回后 C++ 层会保存其中两个函数,分别用于加载内置 C++ 模块和原生 JS 模块的函数。
初始化执行上下文
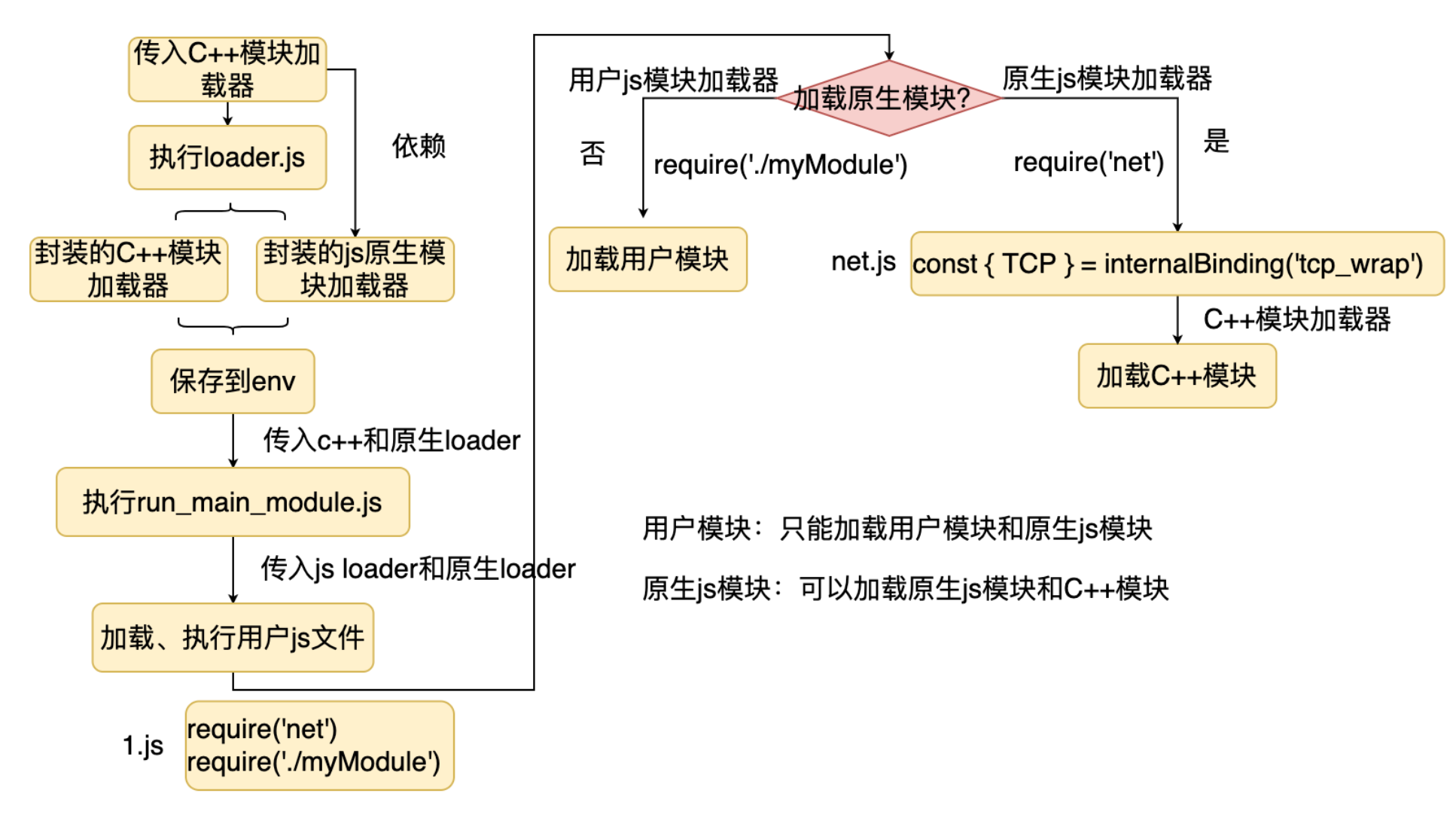
- Node.js 首先传入 C++ 模块加载器,执行 loader.js,loader.js 主要是封装了 C++ 模块加载器和原生 JS 模块加载器,并保存到 env 对象中。
- 接着传入 C++ 和原生 JS 模块加载器,执行 run_main_module.js。
- 在 run_main_module.js 中传入普通 JS 和原生 JS 模块加载器,执行用户的 JS。
假设用户 JS 代码如下:
1 | require('./myModule') |
代码中分别加载了一个用户模块和原生 JS 模块,我们看看加载过程,执行 require 的时候。
- Node.js 首先会判断是否是原生 JS 模块,如果不是则直接加载用户模块,否则,会使用原生模块加载器加载原生 JS 模块。
- 加载原生 JS 模块的时候,如果用到了 C++ 模块,则使用 internalBinding 去加载。
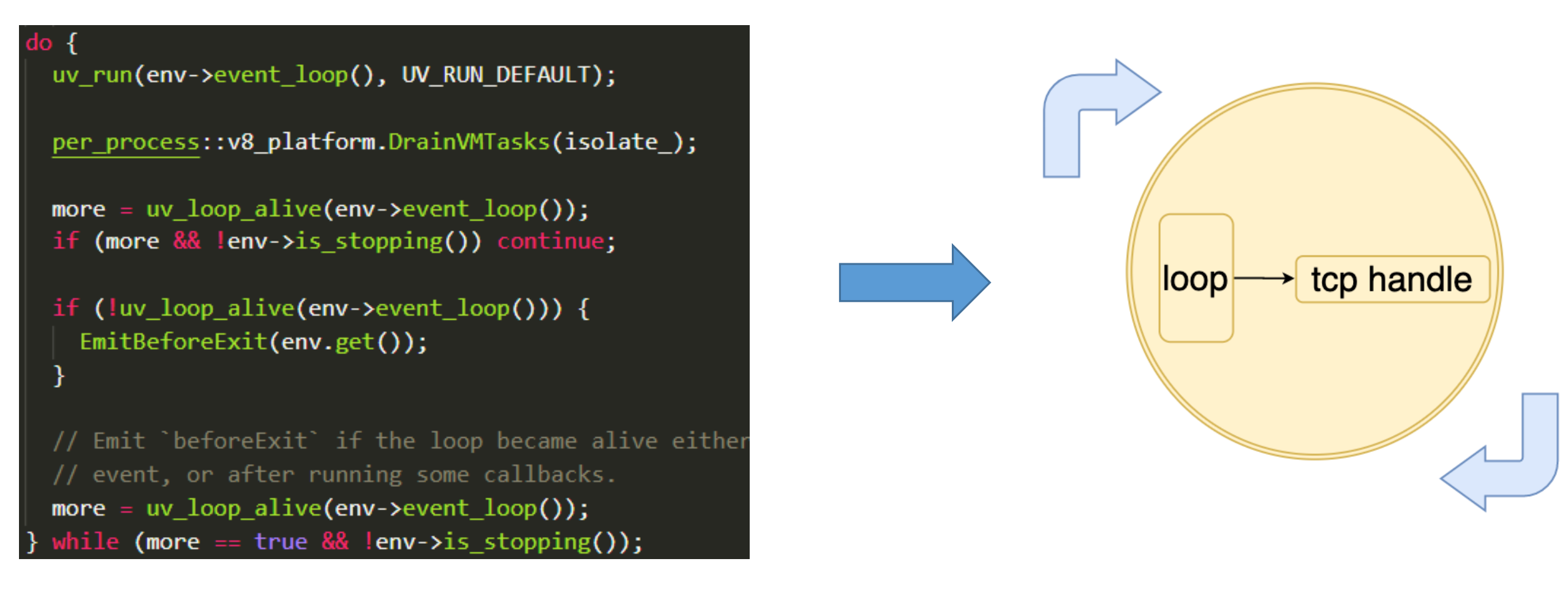
4、执行用户 JS 代码,然后进入 Libuv 事件循环
接着 Node.js 就会执行用户的 JS,通常用户的 JS 会给事件循环生产任务,然后就进入了事件循环系统,比如我们 listen 一个服务器的时候,就会在事件循环中新建一个 TCP handle。Node.js 就会在这个事件
循环中一直运行。
1 | net.createServer(() => {}).listen(80) |
四、事件循环
下面我们看一下事件循环的实现。事件循环主要分为 7 个阶段,timer 阶段主要是处理定时器相关的任务,pending 阶段主要是处理 Poll IO 阶段回调里产生的回调,check、prepare、idle 阶段是自定义的阶段,这三个阶段的任务每次
事件序循环都会被执行,Poll IO 阶段主要是处理网络 IO、信号、线程池等等任务,closing 阶段主要是处理关闭的 handle,比如关闭服务器。

- timer 阶段: 用二叉堆实现,最快过期的在根节点。
- pending 阶段:处理 Poll IO 阶段回调里产生的回调
- check、prepare、idle 阶段:每次事件循环都会被执行。
- Poll IO 阶段:处理文件描述符相关事件。
- closing 阶段:执行调用 uv_close 函数时传入的回调。
下面我们详细看一下每个阶段的实现。

