本文首先会从GraphQL规范讲起,先了解GraphQL语言本身,为什么会有这门语言,以及GraphQL规范中核心定义,然后再去了解GraphQL实现,graphql-js是如何解析,校验,执行GraphQL的。
GraphQL 规范
GraphQL规范是对GraphQL语法的抽象,规范中详细的定义了GraphQL语言的规则,以及GraphQL校验,执行等流程,不同语言的实现都应遵守GraphQL的规范。https://graphql.github.io/graphql-spec/
要想了解GraphQL的原理,阅读规范是必不可少的。我们需要了解的所有细节,都定义在GraphQL规范中。规范就像英语的语法,虽然不会影响我们使用这门语言,但当我们需要细致的研究英语文章时,语法总会是一道跨不过去的坎。
GraphQL规范是会随着发布版本而变化的,就像EcmaScript规范一样,有ES2017,ES2018等,不同的实现可能实现了不同的版本。但GraphQL的实现相对统一,对于JS来说只有graphql-js这一种实现,大家在使用的时候注意一下graphql-js的版本就可以了,可能一些新的特性在旧版本中并没有实现。
GraphQL规范中主要包含6个部分:
- Language: 语言层,定义了GraphQL查询语法,以及GraphQL的词法单元(Source Text)。
- Type System: 类型系统,定义了GraphQL的基本类型的定义,以及描述查询文档类型的Schema
- Introspection: 内省系统,定义了如何通过特定的类型,获取GraphQL内部的定义(Schema的定义)
- Validation: 校验,定义了GraphQL语法的校验规则
- Execution: 执行,定义了GraphQL是如何执行GraphQL请求文档的
- Response: 响应,定义了GraphQL执行结果返回的数据格式
一、起源与历史

在2012年进入了移动网络时代后,Facebook也开始从Web网站转移到Native App,然而旧有的部分接口并不适用于Native的数据展示(接口会直接返回HTML),以及为了应对快速发展的移动端业务,Facebook的工程师开始重构API接口。在重新设计接口的过程中,他们提出了Client优先的设计思想,以通过思考客户端如何展示数据的角度来设计接口。IOS工程师希望能以对象模型的形式返回数据,并可以将接口返回的JSON映射Naitve的模型当中。为了满足客户端的需求,渐渐提出了具有类型和层次结构的接口语言,也就是GraphQL的雏形。
GraphQL最开始只有Query和类型系统等功能,但在工程师上线News Feed的接口并获得成功后,引来了Facebook其他团队的围观,并对GraphQL提出了各种各样的讨论。在不同的讨论之间,GraphQL的Mutation, Subscription, Code Generation, Persistent Query等功能诞生了,在之后还产生了Relay等GraphQL的框架。直到2015年,Facebook的工程师第一次React的会议上公开了GraphQL,但这时GraphQL还只是Facebook内部使用的技术方案,并没有对外发布的计划。但在GraphQL公开以后,社区的呼声很高,都在呼吁能发布公开版本让大家使用。于是Facebook的工程师开始对GraphQL重构,并从内部的业务逻辑中抽离出来,直到发布第一个Preview版本。在发布Preview版本的过程中,还发布了GraphQL语言的实现graphql-js并开源,以及GraphQL的调试工具Graphical。在发布Preview版本后,又对反馈做了些优化和修改,最终于2016年正式发布。
二、设计理念
在了解完GraphQL的历史后,我们在来看GraphQL的设计理念。设计理念直接决定了GraphQL是为了哪些场景而诞生的,以及可以解决什么样的问题。
Hierarchical 分层 现在大部分产品开发都涉及到操作视图的分层。为了满足应用结构的层次性,GraphQL查询也是分层构建的,每个查询和其返回使用了相同的形状,这样的方式在描述数据需求上更为直观。
Product‐centric 产品为中心 GraphQL是一种视图需求驱动的语言,因为主要是前端工程师书写它。GraphQL本身从前端工程师的思想和需求出发,再开发了语言和运行时库以满足这些需求。
Strong‐typing 强类型 每个GraphQL服务器都会构建一个针对应用的类型系统,查询语句就在这个类型系统上下文中执行。对于一个查询语句,GraphQL工具可以在执行以前通过类型系统检查这个查询语句的语法正确性和查询有效性,譬如在开发期,服务器就能保证返回值的形状和特性。
Client‐specified queries 客户端定制 通过类型系统,GraphQL向客户端通告了自己那些可以被消费的能力。而客户端则专注于如何消费这些能力,其查询语句的粒度是字段级的。在大多数没有GraphQL的CS模型应用中,不同的服务端用不同的脚本和入口决定了返回的数据。而GraphQL查询则会返回客户端要求的数据,不多不少。
Introspective 内省 GraphQL是内省的,一个GraphQL服务器的类型系统必须能用GraphQL语言自身来查询。GraphQL的内省特性使之能成为建造通用工具和客户端库的强大平台。
三、GraphQL文档
GraphQL文档描述了客户端发送的查询语句或GraphQL服务可以操作的完整文件(Schema)。GraphQL文档包含了可执行定义和类型定义。
1 | Document: |
无论是GraphQL请求种的查询文档还是服务端定义的Schema都是GraphQL文档的一种,但对于GraphQL服务来说,只有包含OperationDefinition的文档才是可执行的。所以前端所定义的查询语句也是必须包含OperationDefinition的。
1 | OperationDefinition: |
四、GraphQL类型
GraphQL包含6种基本类型和2种包装类型 (NonNullType, ListType)。包装类型顾名思义是对其他类型的包装,无法单独使用。
1 | TypeDefinition: |
- ScalarType(标量类型)和EnumType(枚举类型)是类型定义中的叶子节点。
- ObjectType(对象类型)是所有类型定义的中间节点。
- UnionType(联合类型)和InterfaceType(接口类型)是抽象类型,会拥有其他类型的子类型
GraphQL 实现
GraphQL实现在不同的语言有不同版本的实现,但所有的实现都要遵守GraphQL规范。不同实现中可能的差异在于GraphQL标量类型的转换与校验规则。下面与graphql-js为例,介绍下GraphQL的实现。

graphql-js主要包含以上7个模块,其中最主要的模块是languange, validation, execution这三个模块,这三个模块是对GraphQL规范的核心实现。
一、Language 语法
语法层包含GraphQL规范中定义的语法实现,其主要工作是将GraphQL文档解析成AST语法树,便于之后的校验与执行。我们以下面的查询语句为例,来介绍解析的整个流程。首先我们会调用graphql-js的parse方法。
1 | import { parse } from 'graphql' |
parse会初始化Parser类,并将字符串转换为Source类型的数据结构,Source数据结构只是对源字符串简单的封装,提供了以字符串中莫个offset开始解析的能力,默认offset是1。
1 | { |
在初始化Parser类的同时会调用createLexer创建一个词法分析器,lexer是词法分析的单元,通过匹配特征字符串TokenKind,将源字符串分解成不同的token。
1 | export const TokenKind = Object.freeze({ |
这些Token单元都是GraphQL规范中定义的,有兴趣的同学可以阅读规范中的对应章节。https://graphql.github.io/graphql-spec/draft/#sec-Source-Text
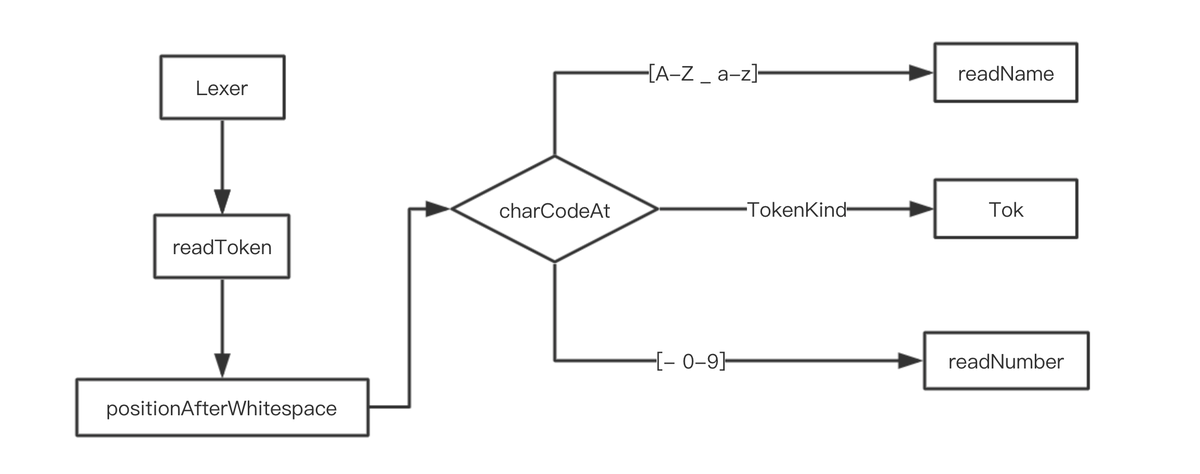
在词法分析的过程中,会跳过GraphQL规范中定义空白符。同时除了上图中的三种分词判断还有STRING,BLOCK_STRING,COMMENT等类型。
Parser会从开始先从lexer去获取第一个token,然后token的类型递归的调用不同的parser方法去解析并在不同的parser方法中不断的调用lexer获取token,直到获取到最后一个token,返回解析后的AST对象。
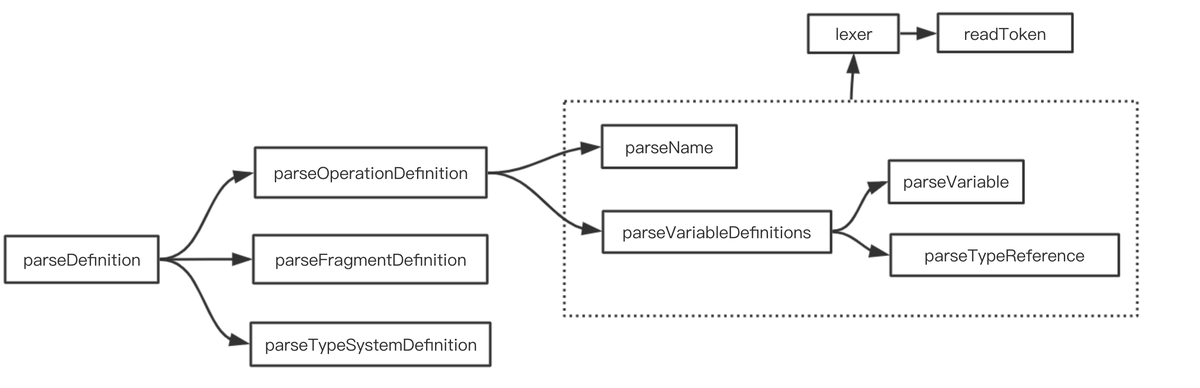
上面的流程图并没有画完,因为parser解析的分支非常多,要对每个可能出现的语法都要做处理。
对于我们上面所举例的查询语句,会有如下的解析流程。
- 获取到第一个NAME类型的token,
- 调用parseDefinition,判断token的值为Query
- 调用parseOperationDefinition,获取下一个token
- 判断token为"(",调用parseVaribaleDefinitions
- 获取下一个token为"$",调用parseVariable
- …
最后会生成如下的AST对象:
1 | { |
二、Validate 验证
GraphQL验证是对解析后的AST进行规则检查的过程,验证不仅会检测语法上的错误,也会检查查询文档,在GraphQL Schema的上下文中是否有歧义或错误。验证需要客户端请求的文档以及GraphQL Schema两个参数,通过深度优先遍历Document的AST对象,对规则中指定的每一个类型进行校验。
graphql-js默认会执行GraphQL规范中定义的所有检测,相关规则可以阅读规范https://graphql.github.io/graphql-spec/draft/#sec-Validation,规范中对与每个检验规则都给出了详细示例。
1 | export const specifiedRules = Object.freeze([ |
其中每个规则都实现了ASTVisitor函数,在深度优先遍历的时候每个节点若实现了对应的方法,将会被执行,如果有错误会保存在透传给所有规则检验函数的context中,当遍历完所有节点后,会返回一个error数组。
1 | var editedAST = visit(ast, { |
所有的规则都通过visit方法去校验AST的每个节点,visit方法还可以指定对某一个AST节点类型进行遍历,只有遍历到某个AST节点时才会触发enter方法和leave方法。
1 | const { visit } = require("graphql/language/visitor"); |
三、Execution 执行
GraphQL通过执行来从请求生成响应。要执行请求,执行器必须接收两个参数,解析过的Document文档,以及GraphQL Schema。
1 | const {parse, buildASTSchema, execute} = require("graphql"); |
GraphQL执行的过程其实就是执行resolver的过程,Document请求的所有field的resolver都会被执行。如果field没有设置resolver,那将会执行默认的resolver,整个执行流程如下。
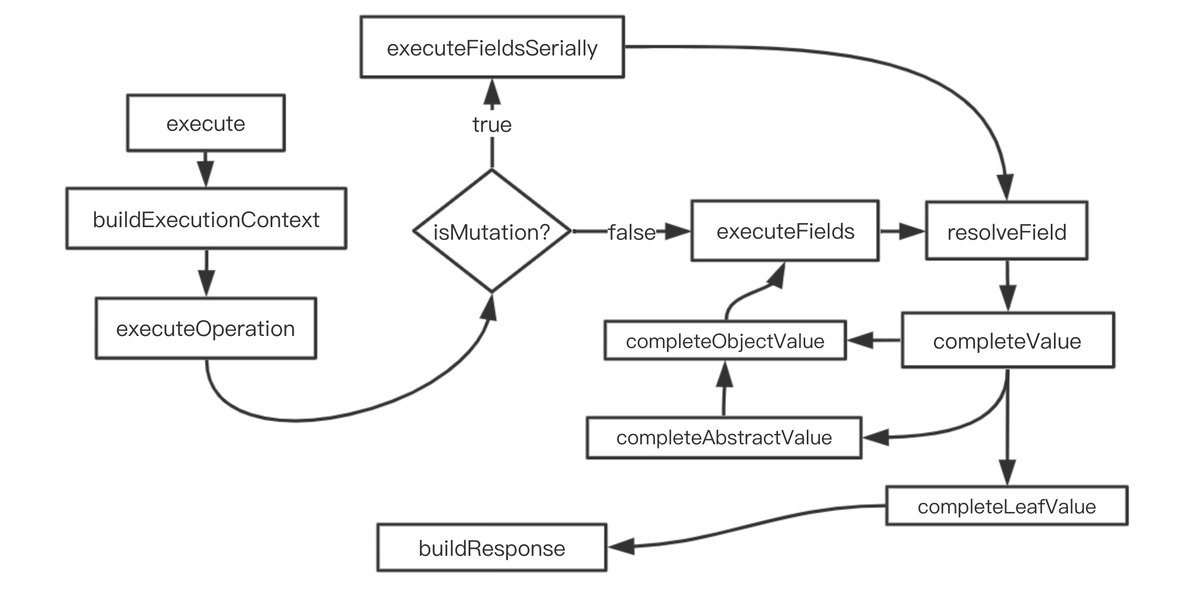
- GraphQL执行首先会生成执行Context,执行Context包含传给execute的原始参数,以及默认的fieldResolver。在整个执行过程中,共用一份Context。
- 判断Operation的类型,如果是Mutation则顺序执行resolveField,否则并行执行resolveField。对于Mutation的顺序执行,保证了请求的幂等性。
1 | { |
- 对当前节点的field执行resolveField,如果存在field.resolver执行resolver,否则执行默认resolver。
- 调用completeValue,对当前field的返回类型进行判断,
- 如果返回值是null或undefined,直接返回,不再执行resolver
- 如果是叶子节点类型(Scalar | Enum),调用Scalar的serialize方法进行序列化,并返回结果
- 如果是List类型,遍历返回值中的每个元素,并递归执行completeValue
- 如果是Object类型,对Object的所有子选择集执行resolveField
- 如果是抽象类型(Union | Interface),确定运行时类型,并执行该类型
- 最后调用buildResponse,返回结果
GraphQL Schema
定义一个GraphQL服务首先要生成GraphQL的Schema,Schema描述了GraphQL服务可以提供哪些接口,以及哪些查询参数。目前有两种方式去定义Schema。 第一种是通过SDL的形式来定义,通常被成为SDL-First或者Schema-First,这种定义方式是以字符串的形式来定义Schema的,可以是graphql的文件,或者直接是代码中定义的字符串。这种的好处就是清晰直观,有很强的可读性和可维护性,但缺少一定的灵活性。因为在Schema定义中没有像查询语句的Fragment,对于类型的复用有些困难,同时Resolver的定义和Schema的定义可能是分离的,我们需要手动连接连接Resolver(虽然有现成的工具帮我们做好了)。
1 | // graphql/shema.graphql |
第二种是通过代码的形式来定义,通常被称为Code-First或者Resolver-First,这种方式直接用graphql-js的对应函数去生成Schema,优势是灵活性很高,Resolver也直接定义在Schema中,但缺点也很明显,代码量多,逻辑不清晰直观。通常只有在需要高度定制,或者动态生成某些类型的时候才使用。
1 | schema.js |
使用代码生成的Schema其实就是GraphQL校验,执行中用到的Schema。使用SDL定义的Schema最终也要生成GraphQLSchema这个函数的实例。最近TS开始流行,其实除了这两种定义的方式,还有了第三种方式,就是使用TypeGraphQL,这种方式结合了SDL和代码定义的优势,不仅有较好可读性,也提供了一定的灵活性。而且提供了TS类型,这是目前通过SDL或者代码都很难做到的。
1 | @ObjectType() |
GraphQL 请求
我们都知道GraphQL请求要定义查询语句,只有包含查询语句的请求才是GraphQL请求,但实际上GraphQL规范中并没有明确定义Client端发出的请求是什么样的,可以POST请求,可以GET请求,请求的参数也可以是任意的,我们来看几个生产环境中使用GraphQL的例子。
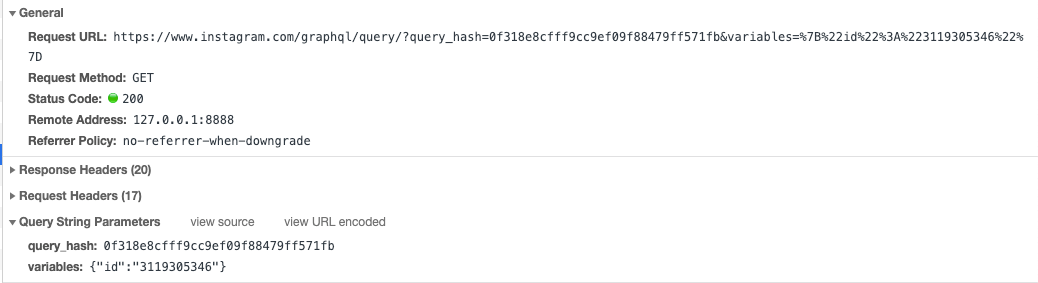
一、Instagram 的 GraphQL 接口
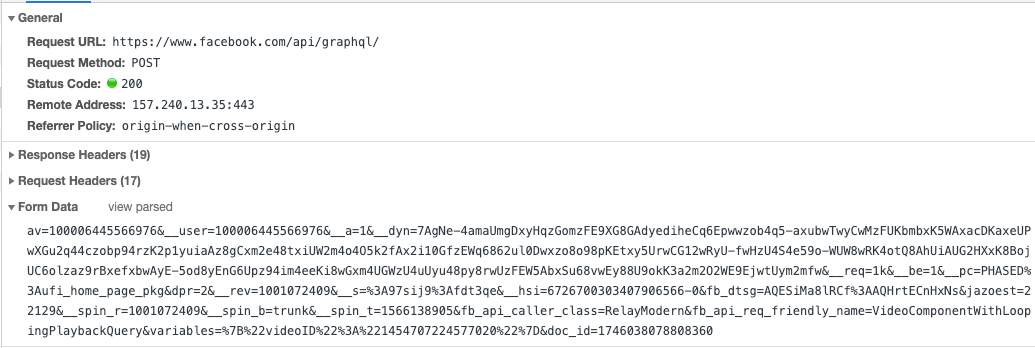
二、Facebook 的 GraphQL 接口
三、特效开发平台的GraphQL接口
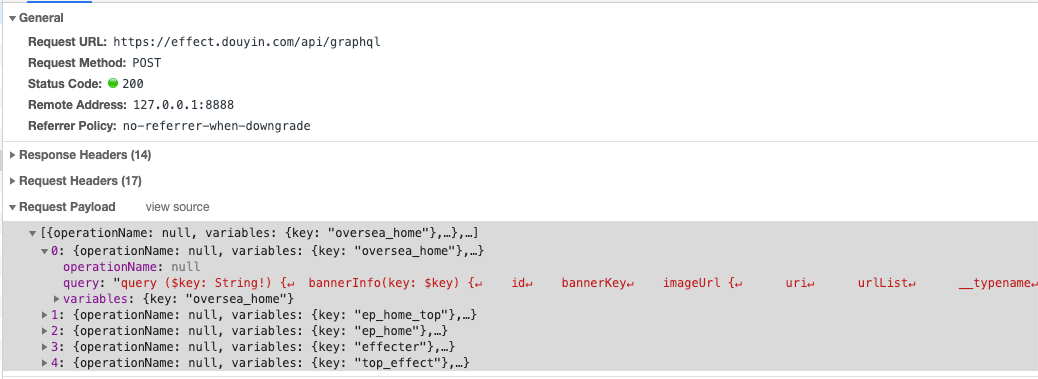
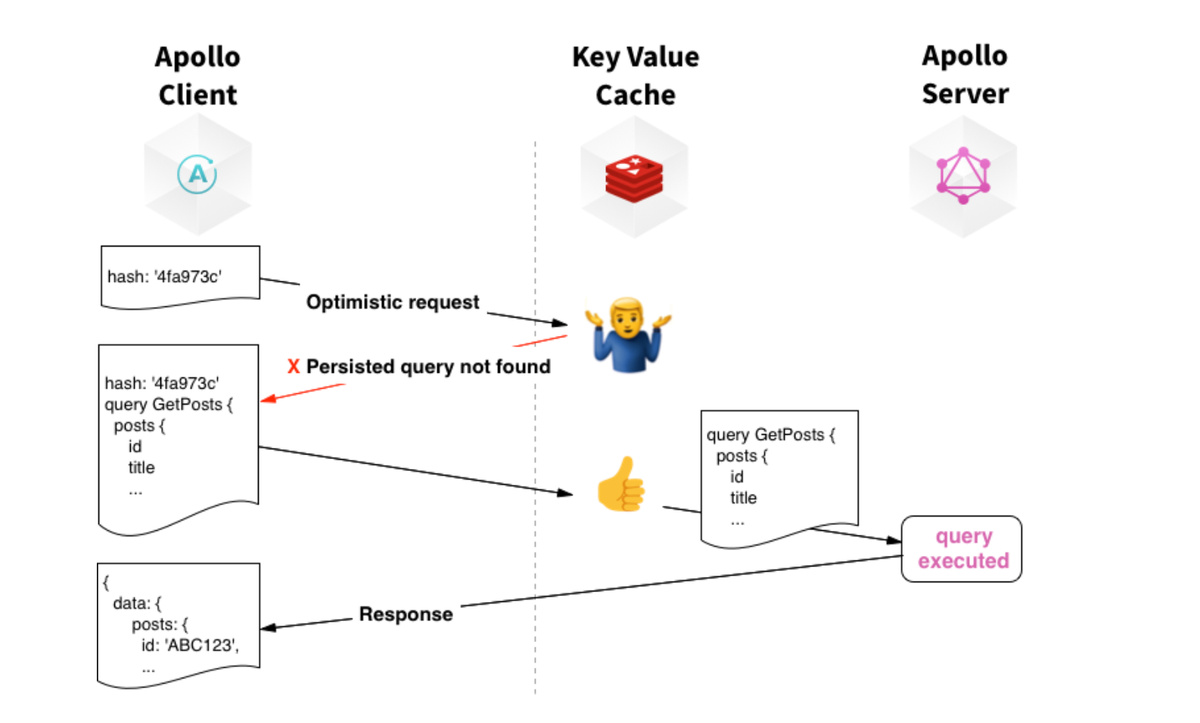
我们看到只有第3个请求是我们常见的GraphQL请求,这也是Apollo Client默认发出的请求格式。但实际上这种格式在生产环境是有一定风险的,对于网络请求我们应该尽量使用不透明的参数。将整个查询语句完全暴露给客户端就相当于公开出了我们的schema,那攻击者就可能猜测出查询语句的字段,如果服务端没有对相应字段做鉴权,那就可能返回不应该返回的数据。所以像Facebook等公司在生产环境都使用了一个不透明的hashKey来代替查询语句。服务端应当只接收可控的hashKey来返回请求。
使用hashKey的另一个好处就是可以减少请求体的长度,众所周知GraphQL的查询语句非常长,如果是复杂的查询,那将极大的增加请求体的大小,而且查询语句一般是要打在前端的bundle中,也会增加bundle的大小,使用hashkey来代替查询语句可以增加请求的性能。在Apollo Server中提供了persisted queries的功能,来支持将查询语句转换为hashKey。Apollo Server中默认的GraphQL请求都是POST请求,但POST请求不利于CDN缓存,persisted queries的另一个功能是支持GET请求,在GET请求中只传递hashKey和variable,以便于做CDN缓存。