在我的博客Webpack运行机制中介绍了 Webpack 的基本工作流程,并介绍了 Compiler 和 Compilation 两个核心模块中的生命周期 Hooks,那么在 Compiler 和 Compilation 的工作流程里,最耗时的阶段分别是哪个呢?
对于 Compiler 实例而言,耗时最长的显然是生成编译过程实例后的 make 阶段,在这个阶段里,会执行模块编译到优化的完整过程。而对于 Compilation 实例的工作流程来说,不同的项目和配置各有不同,但总体而言,编译模块和后续优化阶段的生成产物并压缩代码的过程都是比较耗时的。
实际上不同项目的构建,在整个流程的前期初始化阶段与最后的产物生成阶段的构建时间区别不大。真正影响整个构建效率的还是 Compilation 实例的处理过程,这一过程又可分为两个阶段:编译模块和优化处理,下面针对这两个阶段我们分别介绍对应的优化手段。
直接开搞!

一、编译提效
编译模块阶段所耗的时间是从单个入口点开始,编译每个模块的时间的总和。要提升这一阶段的构建效率,大致可以分为三个方向:
- 减少执行编译的模块。
- 提升单个模块构建的速度。
- 并行构建以提升总体效率。
1、减少执行编译的模块
提升编译模块阶段效率的第一个方向就是减少执行编译的模块。显而易见,如果一个项目每次构建都需要编译 1000 个模块,但是通过分析后发现其中有 500 个不需要编译,显而易见,经过优化后,构建效率可以大幅提升。
(1)IgnorePlugin
有的依赖包,除了项目所需的模块内容外,还会附带一些多余的模块。典型的例子是 moment 这个包,一般情况下在构建时会自动引入其 locale 目录下的多国语言包,这实际上是完全没有必要的,这种情形下我们就可以通过 IgnorePlugin 实现打包时对第三方包指定目录忽略。
使用方法:
1 | // resourceRegExp: A RegExp to test the resource against. |
以 moment 为例:
1 | // webpack.config.js |
在示例中我们通过 IgnorePlugin 忽略了包含 ’./locale/’ 该字段路径的文件目录,但是也使得我们使用的时候不能显示中文语言了,所以这个时候可以手动引入中文语言的目录,这样就实现了只引入必要文件,减少非必要的模块的编译。
(2)按需引入类库模块
第二种典型的减少执行模块的方式是按需引入。这种方式一般适用于工具类库性质的依赖包的优化,典型例子是 lodash 依赖包。通常在项目里我们只用到了少数几个 lodash 的方法,但是构建时却发现构建时引入了整个依赖包,要解决这个问题,效果最佳的方式是在导入声明时只导入依赖包内的特定模块,这样就可以大大减少构建时间,以及产物的体积,除了在导入时声明特定模块之外,还可以使用 babel-plugin-lodash 或 babel-plugin-import 等插件达到同样的效果。
另外,有同学也许会想到 Tree Shaking,这一特性也能减少产物包的体积,但是这里有两点需要注意:
- Tree Shaking 需要相应导入的依赖包使用 ES6 模块化,而 lodash 还是基于 CommonJS ,需要替换为 lodash-es 才能生效。
- 相应的操作是在优化阶段进行的,换句话说,Tree Shaking 并不能减少模块编译阶段的构建时间。
(3)DllPlugin
“DLL” 一词代表微软最初引入的动态链接库。在一个动态链接库中可以包含给其他模块调用的函数和数据。
要给 Web 项目构建接入动态链接库的思想,需要完成以下事情:
- 把网页依赖的基础模块抽离出来,打包到一个个单独的动态链接库中去。一个动态链接库中可以包含多个模块。
- 当需要导入的模块存在于某个动态链接库中时,这个模块不能被再次被打包,而是去动态链接库中获取。
- 页面依赖的所有动态链接库需要被加载。
为什么给 Web 项目构建接入动态链接库的思想后,会大大提升构建速度呢? 原因在于包含大量复用模块的动态链接库只需要编译一次,在之后的构建过程中被动态链接库包含的模块将不会在重新编译,而是直接使用动态链接库中的代码。 由于动态链接库中大多数包含的是常用的第三方模块,例如 react、react-dom,只要不升级这些模块的版本,动态链接库就不用重新编译。
Webpack 已经内置了对动态链接库的支持,需要通过2个内置的插件接入,它们分别是:
- DllPlugin 插件:用于打包出一个个单独的动态链接库文件。
- DllReferencePlugin 插件:用于在主要配置文件中去引入 DllPlugin 插件打包好的动态链接库文件。
下面以基本的 React 项目为例,为其接入 DllPlugin,在开始前先来看下最终构建出的目录结构:
1 | ├── main.js |
其中包含两个动态链接库文件,分别是:
- polyfill.dll.js 里面包含项目所有依赖的 polyfill,例如 Promise、fetch 等 API。
- react.dll.js 里面包含 React 的基础运行环境,也就是 react 和 react-dom 模块。
以 react.dll.js 文件为例,其文件内容大致如下:
1 | var _dll_react = (function(modules) { |
可见一个动态链接库文件中包含了大量模块的代码,这些模块存放在一个数组里,用数组的索引号作为 ID。 并且还通过 _dll_react 变量把自己暴露在了全局中,也就是可以通过 window._dll_react 可以访问到它里面包含的模块。
其中 polyfill.manifest.json 和 react.manifest.json 文件也是由 DllPlugin 生成出,用于描述动态链接库文件中包含哪些模块, 以 react.manifest.json 文件为例,其文件内容大致如下:
1 | { |
可见 manifest.json 文件清楚地描述了与其对应的 dll.js 文件中包含了哪些模块,以及每个模块的路径和 ID。
main.js 文件是编译出来的执行入口文件,当遇到其依赖的模块在 dll.js 文件中时,会直接通过 dll.js 文件暴露出的全局变量去获取打包在 dll.js 文件的模块。 所以在 index.html 文件中需要把依赖的两个 dll.js 文件给加载进去,index.html 内容如下:
1 | <html> |
以上就是所有接入 DllPlugin 后最终编译出来的代码,接下来教你如何实现。
构建出动态链接库文件
构建输出的以下这四个文件
1 | ├── polyfill.dll.js |
和以下这一个文件
1 | ├── main.js |
是由两份不同的构建分别输出的。
动态链接库文件相关的文件需要由一份独立的构建输出,用于给主构建使用。新建一个 Webpack 配置文件 webpack_dll.config.js 专门用于构建它们,文件内容如下:
1 | const path = require('path'); |
使用动态链接库文件
构建出的动态链接库文件用于给其它地方使用,在这里也就是给执行入口使用。
用于输出 main.js 的主 Webpack 配置文件内容如下:
1 | const path = require('path'); |
注意:在 webpack_dll.config.js 文件中,DllPlugin 中的 name 参数必须和 output.library 中保持一致。 原因在于 DllPlugin 中的 name 参数会影响输出的 manifest.json 文件中 name 字段的值, 而在 webpack.config.js 文件中 DllReferencePlugin 会去 manifest.json 文件读取 name 字段的值, 把值的内容作为在从全局变量中获取动态链接库中内容时的全局变量名。
执行构建
在修改好以上两个 Webpack 配置文件后,需要重新执行构建。 重新执行构建时要注意的是需要先把动态链接库相关的文件编译出来,因为主 Webpack 配置文件中定义的 DllReferencePlugin 依赖这些文件。执行构建时流程如下:
- 如果动态链接库相关的文件还没有编译出来,就需要先把它们编译出来。方法是执行 webpack --config webpack_dll.config.js 命令。
- 在确保动态链接库存在时,才能正常的编译出入口执行文件。方法是执行 webpack 命令。这时你会发现构建速度有了非常大的提升。
(4)Externals
Webpack 配置中的 externals 和 DllPlugin 解决的是同一类问题:将依赖的框架等模块从构建过程中移除。它们的区别在于:
- 在 Webpack 的配置方面,externals 更简单,而 DllPlugin 需要独立的配置文件。
- DllPlugin 包含了依赖包的独立构建流程,而 externals 配置中不包含依赖框架的生成方式,通常使用已传入 CDN 的依赖包。
- externals 配置的依赖包需要单独指定依赖模块的加载方式:全局对象、CommonJS、AMD 等。
- 在引用依赖包的子模块时,DllPlugin 无须更改,而 externals 则会将子模块打入项目包中。
使用方法:
1 | externals: string | [string] | object | function | RegExp |
- 字符串
1 | // webpack.config.js |
1 | <!-- index.html --> |
我们以上述示例为例,externals 属性名称是 jquery,表示应该排除 import $ from 'jquery' 中的 jquery 模块。为了替换这个模块,jQuery 的值将被用来检索一个全局的 jQuery 变量。换句话说,当设置为一个字符串时,它将被视为全局的(定义在上面和下面)。
如果想将一个符合 CommonJS 模块化规则的类库外部化,我们可以提供外联类库的类型以及类库的名称。举个例子,如果你想将 fs-extra 从输出的 bundle 中剔除并在运行时中引入它,你可以如下定义:
1 | // webpack.config.js |
这样的做法会让任何依赖的模块都不变,正如以下所示的代码:
1 | import fs from 'fs-extra'; |
会将代码编译成:
1 | const fs = require('fs-extra'); |
- 字符串数组
1 | // webpack.config.js |
subtract: ['./math', 'subtract'] 转换为父子结构,其中 ./math 是父模块,而 bundle 只引用 subtract 变量下的子集。该例子会编译成 require(’./math’).subtract;
- 对象
1 | module.exports = { |
此语法用于描述外部 library 所有可用的访问方式。这里 lodash 这个外部 library 可以在 AMD 和 CommonJS 模块系统中通过 lodash 访问,但在全局变量形式下用 _ 访问。subtract 可以通过全局 math 对象下的属性 subtract 访问(例如 window[‘math’][‘subtract’])。
注:一个形如 { root, amd, commonjs, … } 的对象仅允许用于 libraryTarget: ‘umd’ 这样的配置.它不被允许 用于其它的 library targets 配置值.
- 函数
- function ({ context, request, contextInfo, getResolve }, callback)
- function ({ context, request, contextInfo, getResolve }) => promise // 5.15.0+
对于 webpack 外部化,通过定义函数来控制行为,可能会很有帮助。例如,webpack-node-externals 能够排除 node_modules 目录中所有模块,还提供一些选项,比如白名单 package(whitelist package)。
函数接收两个入参:
- ctx (object):包含文件详情的对象。
- ctx.context (string): 包含引用的文件目录。
- ctc.request (string): 被请求引入的路径。
- ctx.contextInfo (string): 包含 issuer 的信息(如,layer)
- ctx.getResolve 5.15.0+: 获取当前解析器选项的解析函数。
- callback (function (err, result, type)): 用于指明模块如何被外部化的回调函数
回调函数接收三个入参:
- err (Error): 被用于表明在外部外引用的时候是否会产生错误。如果有错误,这将会是唯一被用到的参数。
- result (string [string] object): 描述外部化的模块。可以接受形如 ${type} ${path} 格式的字符串,或者其它标准化外部化模块格式,(string, [string],或 object)。
- type (string): 可选的参数,用于指明模块的类型(如果它没在 result 参数中被指明)。
举个例子:
1 | module.exports = { |
- RegExp
匹配给定正则表达式的每个依赖,都将从输出 bundle 中排除。
1 | module.exports = { |
这个示例中,所有名为 jQuery 的依赖(忽略大小写),或者 $,都会被外部化。
2、提升单个模块构建的速度
提升编译阶段效率的第二个方向,是在保持构建模块数量不变的情况下,提升单个模块构建的速度。具体来说,是通过减少构建单个模块时的一些处理逻辑来提升速度。这个方向的优化主要有以下几种:
(1)include/exclude
include 的用途是只对符合条件的模块使用指定 Loader 进行转换处理。而 exclude 则相反,不对特定条件的模块使用该 Loader。举个例子我们不使用 babel-loader 处理 node_modules 中的模块:
1 | module: { |
这儿需要注意通过 include/exclude 排除的模块,并非不进行编译,只是不通过 babel-loader 而是使用 Webpack 默认的 js 模块编译器进行编译(例如推断依赖包的模块类型,加上装饰代码等)。
(2)noParse
Webpack 配置中的 module.noParse 则是在上述 include/exclude 的基础上,进一步省略了使用默认 js 模块编译器进行编译的时间,忽略的文件中 不应该含有 import, require, define 的调用,或任何其他导入机制。忽略大型的 library 可以提高构建性能。
1 | module.exports = { |
1 | module.exports = { |
(3)SourceMap
SourceMap 的不同配置对于项目的构建时间都是不同的,对于生产环境的代码构建而言,会根据项目实际情况判断是否开启 Source Map。在开启 Source Map 的情况下,优先选择与源文件分离的类型,例如 “source-map”。有条件也可以配合错误监控系统,将 Source Map 的构建和使用在线下监控后台中进行,以提升普通构建部署流程的速度。
(4)TypeScript编译优化
Webpack 中编译 TS 有两种方式:使用 ts-loader 或使用 babel-loader。其中,在使用 ts-loader 时,由于 ts-loader 默认在编译前进行类型检查,因此编译时间往往比较慢,通过加上配置项 transpileOnly: true,可以在编译时忽略类型检查,从而大大提升 TS 模块的编译速度,而 babel-loader 则需要单独安装 @babel/preset-typescript 来支持编译 TS(Babel 7 之前的版本则还是需要使用 ts-loader)。babel-loader 的编译效率与上述 ts-loader 优化后的效率相当。
不过单独使用这一功能就丧失了 TS 中重要的类型检查功能,因此在许多脚手架中往往配合 ForkTsCheckerWebpackPlugin 一同使用。
(5)Resolve
Webpack 中的 resolve 配置制定的是在构建时指定查找模块文件的规则,例如:
- resolve.modules:指定查找模块的目录范围。
- resolve.extensions:指定查找模块的文件类型范围。
- resolve.mainFields:指定查找模块的 package.json 中主文件的属性名。
- resolve.symlinks:指定在查找模块时是否处理软连接。
- resolve.alias:创建 import 或 require 的别名,来确保模块引入变得更简单
这些规则在处理每个模块时都会有所应用,因此尽管对小型项目的构建速度来说影响不大,但对于大型的模块众多的项目而言,这些配置的变化就可能产生客观的构建时长区别
1 | module.exports = { |
3、并行构建以提升
第三个编译阶段提效的方向是使用并行的方式来提升构建的效率。并行构建的方案早在 Webpack 2 时代已经出现,随着目前最新稳定版本 Webpack 4 的发布,人们发现在一般项目的开发阶段和小型项目的各构建流程中已经用不到这种并发的思路了,因为在这些情况下,并发所需要的多进程管理与通信所带来的额外时间成本可能会超过使用工具带来的收益。但是在大中型项目的生产环境构建时,这类工具仍有发挥作用的空间。这里我们介绍两类并行构建的工具: HappyPack 与 thread-loader,以及 parallel-webpack。
(1)HappyPack 与 thread-loader
这两种工具的本质作用相同,都作用于模块编译的 Loader 上,每次 webpack 解析一个模块,它们都会将该模块及该模块的依赖分配给 worker 进程中,以开启多进程的方式加速编译。HappyPack 诞生较早,在 webpack 3 的版本中使用比较广泛,但是 webpack 4 的版本中官方推出了 thread-loader,并且 thread-loader 参照 HappyPack 的效果实现了更符合 Webpack 中 Loader 的编写方式。
1 | // 注意如果 webpack 的版本为 4 的话必须保证 HappyPack 的版本在 5 以上 |
1 | // 注意如果 webpack 的版本为 4 的话必须保证 HappyPack 的版本在 5 以上 |
(2)parallel-webpack
并发构建的第二种场景是针对与多配置构建。Webpack 的配置文件可以是一个包含多个子配置对象的数组,在执行这类多配置构建时,默认串行执行,而通过 parallel-webpack,就能实现相关配置的并行处理。
1 | // webpack.config.js |
1 | // webpack.ignore.config.js |
1 | // webpack.inexclude.config.js |
二、优化提效
在文件生成的前的优化阶段可以细分为 12 个子任务,每个任务依次对数据进行一定的处理,并将结果传递给下一任务:
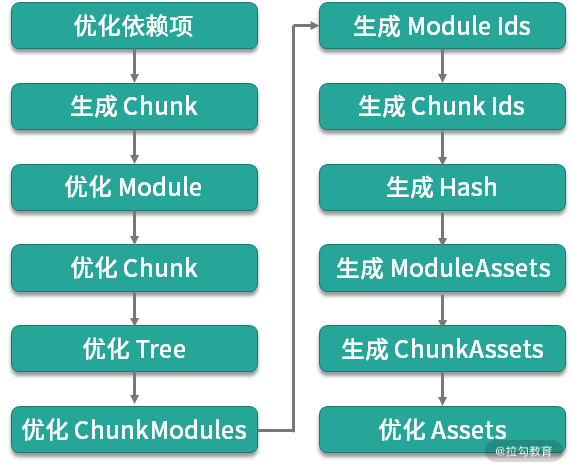
因此,这一阶段的优化也可以分为两个不同的方向:
- 针对某些任务,使用效率更高的工具或配置项,从而提升当前任务的工作效率。
- 提升特定任务的优化效果,以减少传递给下一任务的数据量,从而提升后续环节的工作效率。
1、以提升当前任务工作效率为目标的方案
一般在项目的优化阶段,主要耗时的任务有两个:一个是生成 ChunkAssets,即根据 Chunk 信息生成 Chunk 的产物代码;另一个是优化 Assets,即压缩 Chunk 产物代码。
第一个任务主要在 Webpack 引擎内部的模块中处理,相对而言优化手段较少,主要集中在利用缓存方面。而在压缩 Chunk 产物代码的过程中会用到一些第三方插件,选择不同的插件,以及插件中的不同配置都可能会对其中的效率产生影响。
(1)代码压缩
面向 JS 的压缩工具:
Webpack 4 中内置了 TerserWebpackPlugin 作为默认的 JS 压缩工具,之前的版本则需要在项目配置中单独引入,早期主要使用的是 UglifyJSWebpackPlugin。这两个 Webpack 插件内部的压缩功能分别基于 Terser 和 UglifyJS。
从第三方的测试结果看,两者在压缩效率与质量方面差别不大,但 Terser 整体上略胜一筹。
Terser 原本是 Fork 自 uglify-es 的项目,其绝大部分的 API 和参数都与 uglify-es 和 uglify-js@3 兼容。因此,两者对应参数的作用与优化方式也基本相同,这里就以 Terser 为例来分析其中的优化方向。
在作为 Webpack 插件的 TerserWebpackPlugin 中,对执行效率产生影响的配置主要分为 3 个方面:
- Cache 选项:默认开启,使用缓存能够极大程度上提升再次构建时的工作效率。
- Parallel 选项:默认开启,并发选项在大多数情况下能够提升该插件的工作效率,但具体提升的程度则因项目而异。在小型项目中,多进程通信的额外消耗可能会抵消其带来的益处。
- terserOptions 选项:即 Terser 工具中的 minify 选项集合。这些选项是对具体压缩处理过程产生影响的配置项。我们主要来看其中的compress和mangle选项,不同选项的压缩结果如下面的代码所示:
1 | // 源代码./src/example-terser-opts.js |
从上面的例子中可以看到:
- compress 参数的作用是执行特定的压缩策略,例如省略变量赋值的语句,从而将变量的值直接替换到引入变量的位置上,减小代码体积。而当 compress 参数为 false 时,这类压缩策略不再生效,示例代码压缩后的体积从 1.16KB 增加到 1.2KB,对压缩质量的影响有限。
- mangle 参数的作用是对源代码中的变量与函数名称进行压缩,当参数为 false 时,示例代码压缩后的体积从 1.16KB 增加到 1.84KB,对代码压缩的效果影响非常大。
面向CSS的压缩工具
CSS 同样有几种压缩工具可供选择:OptimizeCSSAssetsPlugin(在 Create-React-App 中使用)、OptimizeCSSNanoPlugin(在 VUE-CLI 中使用),以及 CSSMinimizerWebpackPlugin(2020 年 Webpack 社区新发布的 CSS 压缩插件)。
这三个插件在压缩 CSS 代码功能方面,都默认基于 cssnano 实现,因此在压缩质量方面没有什么差别。
在压缩效率方面,首先值得一提的是最新发布的 CSSMinimizerWebpackPlugin,它支持缓存和多进程,这是另外两个工具不具备的。而在非缓存的普通压缩过程方面,整体上 3 个工具相差不大,不同的参数结果略有不同,但考虑到只有这一新发布的插件支持缓存和多进程等对项目构建效率影响明显的功能,因此比较推荐使用它。
(2)缓存优化
缓存优化我们分别根据编译阶段和缓存优化阶段来分别进行梳理:
1> 编译阶段的缓存优化
编译过程的耗时点主要在使用不同加载器(Loader)来编译模块的过程。下面我们来分别看下几个典型 Loader 中的缓存处理:
Babel-loader
Babel-loader 是绝大部分项目中会使用到的 JS/JSX/TS 编译器。在 Babel-loader 中,与缓存相关的设置主要有:
- cacheDirectory:默认为 false,即不开启缓存。当值为 true 时开启缓存并使用默认缓存目录(./node_modules/.cache/babel-loader/),也可以指定其他路径值作为缓存目录。
- cacheIdentifier:用于计算缓存标识符。默认使用 Babel 相关依赖包的版本、babelrc 配置文件的内容,以及环境变量等与模块内容一起参与计算缓存标识符。如果上述内容发生变化,即使模块内容不变,也不能命中缓存。
- cacheCompression:默认为 true,将缓存内容压缩为 gz 包以减小缓存目录的体积。在设为 false 的情况下将跳过压缩和解压的过程,从而提升这一阶段的速度。
1 | module.exports = { |
Cache-loader
在编译过程中利用缓存的第二种方式是使用 Cache-loader。在使用时,需要将 cache-loader 添加到对构建效率影响较大的 Loader(如 babel-loader 等)之前,
1 | // ./webpack.cache.config.js |
但实际编译时我们发现使用 cache-loader 后,比使用 babel-loader 的开启缓存选项后的构建时间更短,主要原因是 babel-loader 中的缓存信息较少,而 cache-loader 中存储的Buffer 形式的数据处理效率更高。下面的示例代码,是 babel-loader 和 cache-loader 入口模块的缓存信息对比:
1 | //babel-loader中的缓存数据 |
2> 优化打包阶段的缓存优化
生成 ChunkAsset 时的缓存优化
在 Webpack 4 中,生成 ChunkAsset 过程中的缓存优化是受限制的:只有在 watch 模式下,且配置中开启 cache 时(development 模式下自动开启)才能在这一阶段执行缓存的逻辑。这是因为,在 Webpack 4 中,缓存插件是基于内存的,只有在 watch 模式下才能在内存中获取到相应的缓存数据对象,在 Webpack 5 中这一问题得到解决,这个我们在后文中会详细介绍。
代码压缩时的缓存优化
前文提到在代码压缩阶段,对于 JS 的压缩,TerserWebpackPlugin 和 UglifyJSPlugin 都是支持缓存设置的。而对于 CSS 的压缩,目前最新发布的 CSSMinimizerWebpackPlugin 支持且默认开启缓存,其他的插件如 OptimizeCSSAssetsPlugin 和 OptimizeCSSNanoPlugin 目前还不支持使用缓存。
Webpack 4 内置了压缩插件 TerserWebpackPlugin,且默认开启了缓存参数,这里再来看一下 CSSMinimizerWebpackPlugin:
1 | const MiniCssExtractPlugin = require('mini-css-extract-plugin') |
3> 编译阶段的缓存失效
编译阶段的执行时间由每个模块的编译时间相加而成。在开启缓存的情况下,代码发生变化的模块将被重新编译,但不影响它所依赖的及依赖它的其他模块,其他模块将继续使用缓存。因此,这一阶段不需要考虑缓存失效扩大化的问题。
4> 优化打包阶段的缓存失效
优化打包阶段的缓存失效问题则需要引起注意。在使用缓存快速构建后,当我们任意修改入口文件的代码后会发现,代码压缩阶段的时间再次变为和初次构建时相近,也就是说,这一 Chunk 的 Terser 插件的缓存完全失效了,之所以会出现这样的结果,是因为,尽管在模块编译阶段每个模块是单独执行编译的,但是当进入到代码压缩环节时,各模块已经被组织到了相关联的 Chunk 中,任何一个模块发生变化都会导致整个 Chunk 的内容发生变化,而使之前保存的缓存失效。
在知道了失效原因后,对应的优化思路也就显而易见了:尽可能地把那些不变的处理成本高昂的模块打入单独的 Chunk 中。这就涉及了 Webpack 中的分包配置——splitChunks。
5> 其他使用缓存的注意事项
CI/CD 中的缓存目录问题
在许多自动化集成的系统中,项目的构建空间会在每次构建执行完毕后,立即回收清理。在这种情况下,默认的项目构建缓存目录(node_mo dules/.cache)将无法留存,导致即使项目中开启了缓存设置,也无法享受缓存的便利性,反而因为需要写入缓存文件而浪费额外的时间。因此,在集成化的平台中构建部署的项目,如果需要使用缓存,则需要根据对应平台的规范,将缓存设置到公共缓存目录下。
缓存的清理
缓存的便利性本质在于用磁盘空间换取构建时间。对于一个大量使用缓存的项目,随着时间的流逝,缓存空间会不断增大。这在只有少数项目的个人电脑中还不是非常大的问题,但对于上述多项目的集成环境而言,则需要考虑对缓存区域的定期清理。
与产物的持久化缓存相区别
如何在 Webpack 中生成产物的持久化缓存方法(即那些我们比较熟悉的 hash、chunkhash、contenthash),但是它们影响的主要所影响的是项目访问的性能,而对构建的效率没有影响。
2、已提升后续环节工作效率为目标的方案
优化阶段的另一类优化方向是通过对本环节的处理减少后续环节处理内容,以便提升后续环节的工作效率。最主要的两个手段分别是 Split Chunks 和 Tree Shaking。
(1)Split Chunks
Split Chunks是指在 Chunk 生成之后,将原先以入口点来划分的 Chunks 根据一定的规则(例如异步引入或分离公共依赖等原则),分离出子 Chunk 的过程,详情可见我的博客Webpack中的CodeSplitting。
Split Chunks 有诸多优点,例如有利于缓存命中、有利于运行时的持久化文件缓存等。其中有一类情况能提升后续环节的工作效率,即通过分包来抽离多个入口点引用的公共依赖:
1 | // ./src/example-split1.js |
在这个示例中,有两个入口文件引入了相同的依赖包 lodash,在没有额外设置分包的情况下, lodash 被同时打入到两个产物文件中,在后续的压缩代码阶段耗时 1740ms。而在设置分包规则为 chunks:‘all’ 的情况下,通过分离公共依赖到单独的 Chunk,使得在后续压缩代码阶段,只需要压缩一次 lodash 的依赖包代码,从而减少了压缩时长,总耗时为 1036ms。
这里起作用的是 Webpack 4 中内置的 SplitChunksPlugin,该插件在 production 模式下默认启用。其默认的分包规则为 chunks: 'async',作用是分离动态引入的模块 (import('...')),在处理动态引入的模块时能够自动分离其中的公共依赖。
但是对于示例中多入口静态引用相同依赖包的情况,则不会处理分包。而设置为 chunks: ‘all’,则能够将所有的依赖情况都进行分包处理,从而减少了重复引入相同模块代码的情况。SplitChunksPlugin 的工作阶段是在optimizeChunks 阶段(Webpack 4 中是在 optimizeChunksAdvanced,在 Webpack 5 中去掉了 basic 和 advanced,合并为 optimizeChunks),而压缩代码是在 optimizeChunkAssets 阶段,从而起到提升后续环节工作效率的作用。
(2)Tree Shaking
Tree Shaking 是指在构建打包过程中,移除那些引入但未被使用的无效代码(Dead-code elimination)。这种优化手段最早应用于在 Rollup 工具中,而在 Webpack 2 之后的版本中, Webpack 开始内置这一功能。不过 Tree Shaking 的使用需要注意以下几点:
-
ES6 模块: 首先,只有 ES6 类型的模块才能进行Tree Shaking。因为 ES6 模块的依赖关系是确定的,因此可以进行不依赖运行时的静态分析,而 CommonJS 类型的模块则不能。因此,CommonJS 类型的模块 lodash,在无论哪种引入方式下都不能实现 Tree Shaking,而需要依赖第三方提供的插件(例如 babel-plugin-lodash 等)才能实现动态删除无效代码。而 ES6 风格的模块 lodash-es,则可以进行 Tree Shaking 优化。
-
引入方式:以 default 方式引入的模块,无法被 Tree Shaking;而引入单个导出对象的方式,无论是使用 import * as xxx 的语法,还是 import {xxx} 的语法,都可以进行 Tree Shaking。
-
sideEffects:在 Webpack 4 中,会根据依赖模块 package.json 中的 sideEffects 属性来确认对应的依赖包代码是否会产生副作用。只有 sideEffects 为 false 的依赖包(或不在 sideEffects 对应数组中的文件),才可以实现安全移除未使用代码的功能。在上面的例子中,如果我们查看 lodash-es 的 package.json 文件,可以看到其中包含了 “sideEffects”:false 的描述。此外,在 Webpack 配置的加载器规则和优化配置项中,分别有 rule.sideEffects(默认为 false)和 optimization.sideEffects(默认为 true)选项,前者指代在要处理的模块中是否有副作用,后者指代在优化过程中是否遵循依赖模块的副作用描述。尤其前者,常用于对 CSS 文件模块开启副作用模式,以防止被移除。
-
Babel:在 Babel 7 之前的babel-preset-env中,modules 的默认选项为 ‘commonjs’,因此在使用 babel 处理模块时,即使模块本身是 ES6 风格的,也会在转换过程中,因为被转换而导致无法在后续优化阶段应用 Tree Shaking。而在 Babel 7 之后的 @babel/preset-env 中,modules 选项默认为 ‘auto’,它的含义是对 ES6 风格的模块不做转换(等同于 modules: false),而将其他类型的模块默认转换为 CommonJS 风格。因此我们会看到,后者即使经过 babel 处理,也能应用 Tree Shaking。
三、增量构建
虽然前面我们介绍了很多 webpack 构建优化的办法,但是我们发现一个问题却迟迟没有得到解决,那就是尽管只改动了一行代码,但是在执行构建时,要完整执行所有模块的编译、优化和生成产物的处理过程,而不是只需要处理所改动的文件。那么如何实现只编译打包我们所改动的文件呢?
在开启 devServer的时候,当我们执行 webpack-dev-server 命令后,Webpack 会进行一次初始化的构建,构建完成后启动服务并进入到等待更新的状态。当本地文件有变更时,Webpack 几乎瞬间将变更的文件进行编译,并将编译后的代码内容推送到浏览器端。你会发现,这个文件变更后的处理过程就符合上面所说的只编译打包改动的文件的操作,这也被称为“增量构建”
1 | module.exports = { |
那么为什么在开发服务模式下可以实现增量构建的效果,而在生产环境下不行呢?
1、增量构建的影响因素
(1)watch配置
在上面的增量构建过程中,第一个想到的就是需要监控文件的变化。显然,只有得知变更的是哪个文件后,才能进行后续的针对性处理。要实现这一点也很简单,在 Webpack 中启用 watch 配置即可,此外在使用 devServer 的情况下,该选项会默认开启。那么,如果在生产模式下开启 watch 配置,是不是再次构建时,就会按增量的方式执行呢?
1 | module.exports = { |
但是我们发现在生产模式下开启 watch 配置后,相比初次构建,再次构建所编译的模块数量并未减少,即使只改动了一个文件,也仍然会对所有模块进行编译。因此可以得出结论,在生产环境下只开启 watch 配置后的再次构建并不能实现增量构建。
(2)cache配置
仔细查阅 Webpack 的配置项文档,会在菜单最下方的“其他选项”一栏中找到 cache 选项(需要注意是 Webpack 4 版本的文档,Webpack 5 中这一选项会有大的改变)。这一选项的值有两种类型:布尔值和对象类型。一般情况下默认为false,即不使用缓存,但在开发模式开启 watch 配置的情况下,cache 的默认值变更为true。此外,如果 cache 传值为对象类型,则表示使用该对象来作为缓存对象,这往往用于多个编译器 compiler 的调用情况。
下面我们就来看一下,在生产模式下,如果watch 和 cache 都为 true,结果会如何?

正如我们所期望的,再次构建时,在编译模块阶段只对有变化的文件进行了重新编译,实现了增量编译的效果。
但是美中不足的是,在优化阶段压缩代码时仍然耗费了较多的时间。这一点很容易理解:我们将提及较大的依赖模块和入口模块打入了同一个 Chunk 中,即使修改的模块是单独分离的 bar.js,但它的产物名称的变化仍然需要反映在入口 Chunk 的 runtime 模块中。因此入口 Chunk 也需要跟着重新压缩而无法复用压缩缓存数据。因此我们还可以通过 split chunks 进一步优化构建速度。
2、增量构建的实现原理
(1)watch 配置的作用
watch 配置的具体逻辑在 Webpack 的 Watching.js 中。查看源码可以看到,在它构建相关的 _go 方法中,执行的依然是 compiler实例的 compile 方法,这一点与普通构建流程并无区别。真正的区别在于,在 watch 模式下,构建完成后并不自动退出,因此构建上下文的对象(包括前一次构建后的缓存数据对象)都可以保留在内存中,并在 rebuild 时重复使用,如下面的代码所示:
1 | // lib/Watching.js |
(2)cache 配置的作用
cache 配置的源码逻辑主要涉及两个文件:CachePlugin.js 和 Compilation.js。其中 CachePlugin.js 的核心作用是将该插件实例的 cache 属性传入 compilation 实例中,如下面的代码所示:
1 | // lib/CachePlugin.js |
而在 Compilation.js 中,运用 cache 的地方有两处:
- 在编译阶段添加模块时,若命中缓存module,则直接跳过该模块的编译过程(与 cache-loader 等作用于加载器的缓存不同,此处的缓存可直接跳过 Webpack 内置的编译阶段)。
- 在创建 Chunk 产物代码阶段,若命中缓存Chunk,则直接跳过该 Chunk 的产物代码生成过程。
1 | // lib/Compilation.js |
以上就是 Webpack 4 中 watch 和 cache 配置的作用原理。通过 Webpack 内置的 cache 插件,将整个构建中相对耗时的两个内部处理环节——编译模块和生成产物,进行缓存的读写处理,从而实现增量构建处理。那么我们是不是就可以在生产环境下直接使用这个方案呢?
3、生产环境下使用增量构建的阻碍
增量构建之所以快是因为将构建所需的数据(项目文件、node_modules 中的文件数据、历史构建后的缓存数据等)都保留在内存中。在 watch 模式下保留着构建使用的 Node 进程,使得下一次构建时可以直接读取内存中的数据。
而生产环境下的构建通常在集成部署系统中进行。对于管理多项目的构建系统而言,构建过程是任务式的:任务结束后即结束进程并回收系统资源。对于这样的系统而言,增量构建所需的保留进程与长时间占用内存,通常都是不可接受的。
因此,基于内存的缓存数据注定无法运用到生产环境中。要想在生产环境下提升构建速度,首要条件是将缓存写入到文件系统中。只有将文件系统中的缓存数据持久化,才能脱离对保持进程的依赖,你只需要在每次构建时将缓存数据读取到内存中进行处理即可。事实上,这也是上一课时中讲到的那些 Loader 与插件中的缓存数据的存储方式。
遗憾的是,Webpack 4 中的 cache 配置只支持基于内存的缓存,并不支持文件系统的缓存。因此,我们只能通过一些支持缓存的第三方处理插件将局部的构建环节应用“增量处理”。
不过好消息是 Webpack 5 中正式支持基于文件系统的持久化缓存(Persistent Cache)。
四、Webpack 5的优化
Webpack 5 中的变化有很多,完整的功能变更清单参见官方文档,这里我们介绍其中与构建效率相关的几个主要功能点:
- Persistent Caching
- Tree Shaking
- Logs
1、Persistent Caching
1 | module.exports = { |
(1)Cache基本配置
在 Webpack 4 中,cache 只是单个属性的配置,所对应的赋值为 true 或 false,用来代表是否启用缓存,或者赋值为对象来表示在构建中使用的缓存对象。而在 Webpack 5 中,cache 配置除了原本的 true 和 false 外,还增加了许多子配置项,例如:
- cache.type:缓存类型。值为 'memory’或‘filesystem’,分别代表基于内存的临时缓存,以及基于文件系统的持久化缓存。在选择 filesystem 的情况下,下面介绍的其他属性生效。
- cache.cacheDirectory:缓存目录。默认目录为 node_modules/.cache/webpack。
- cache.name:缓存名称。同时也是 cacheDirectory 中的子目录命名,默认值为 Webpack 的 {config.mode}。
- cache.cacheLocation:缓存真正的存放地址。默认使用的是上述两个属性的组合:path.resolve(cache.cacheDirectory, cache.name)。该属性在赋值情况下将忽略上面的 cacheDirectory 和 name 属性。
(2)单个模块的缓存失效
Webpack 5 会跟踪每个模块的依赖项:fileDependencies、contextDependencies、missingDependencies。当模块本身或其依赖项发生变更时,Webpack 能找到所有受影响的模块,并重新进行构建处理。
这里需要注意的是,对于 node_modules 中的第三方依赖包中的模块,出于性能考虑,Webpack 不会跟踪具体模块文件的内容和修改时间,而是依据依赖包里package.json 的 name 和 version 字段来判断模块是否发生变更。因此,单纯修改 node_modules 中的模块内容,在构建时不会触发缓存的失效。
(3)全局的缓存失效
当模块代码没有发生变化,但是构建处理过程本身发生变化时(例如升级了 Webpack 版本、修改了配置文件、改变了环境变量等),也可能对构建后的产物代码产生影响。因此在这种情况下不能复用之前缓存的数据,而需要让全局缓存失效,重新构建并生成新的缓存。在 Webpack 5 中共提供了 3 种不同维度的全局缓存失效配置。
buildDependencies
第一种配置是cache.buildDependencies,用于指定可能对构建过程产生影响的依赖项。
它的默认选项是{defaultWebpack: ["webpack/lib"]}。这一选项的含义是,当 node_modules 中的 Webpack 或 Webpack 的依赖项(例如 watchpack 等)发生变化时,当前的构建缓存即失效。
上述选项是默认内置的,无须写在项目配置文件中。配置文件中的 buildDenpendencies 还支持增加另一种选项 {config: [__filename]},它的作用是当配置文件内容或配置文件依赖的模块文件发生变化时,当前的构建缓存即失效。
version
第二种配置是 cache.version。当配置文件和代码都没有发生变化,但是构建的外部依赖(如环境变量)发生变化时,预期的构建产物代码也可能不同。这时就可以使用 version 配置来防止在外部依赖不同的情况下混用了相同的缓存。例如,可以传入 cache: {version: process.env.NODE_ENV},达到当不同环境切换时彼此不共用缓存的效果。
name
缓存的名称除了作为默认的缓存目录下的子目录名称外,也起到区分缓存数据的作用。例如,可以传入 cache: {name: process.env.NODE_ENV}。这里有两点需要补充说明:
name 的特殊性:与 version 或 buildDependencies 等配置不同,name 在默认情况下是作为缓存的子目录名称存在的,因此可以利用 name 保留多套缓存。在 name 切换时,若已存在同名称的缓存,则可以复用之前的缓存。与之相比,当其他全局配置发生变化时,会直接将之前的缓存失效,即使切换回之前已缓存过的设置,也会当作无缓存处理。
当 cacheLocation 配置存在时,将忽略 name 的缓存目录功能,上述多套缓存复用的功能也将失效。
其他
除了上述介绍的配置项外,cache 还支持其他属性:managedPath、hashAlgorithm、store、idleTimeout 等,具体功能可以通过官方文档进行查询。
此外,在 Webpack 4 中,部分插件是默认启用缓存功能的(例如压缩代码的 Terser 插件等),项目在生产环境下构建时,可能无意识地享受缓存带来的效率提升,但是在 Webpack 5 中则不行。无论是否设置 cache 配置,Webpack 5 都将忽略各插件的缓存设置(例如 TerserWebpackPlugin),而由引擎自身提供构建各环节的缓存读写逻辑。因此,项目在迁移到 Webpack 5 时都需要通过上面介绍的 cache 属性来单独配置缓存。
除此之外通过对 compiler.cache.hook.get 的追踪不难发现:持久化缓存一共影响下面这些环节与内置的插件:
- 编译模块:ResolverCachePlugin、Compilation/modules。
- 优化模块:FlagDependencyExportsPlugin、ModuleConcatenationPlugin。
- 生成代码:Compilation/codeGeneration、Compilation/assets。
- 优化产物:TerserWebpackPlugin、RealContentHashPlugin。
正是通过这样多环节的缓存读写控制,才打造出 Webpack 5 高效的持久化缓存功能。
2、Tree Shaking
Webpack 5 中的另一项优化体现在 Tree Shaking 功能方面。Webpack 4 中的 Tree Shaking 功能在使用上存在限制:只支持 ES6 类型的模块代码分析,且需要相应的依赖包或需要函数声明为无副作用等。这使得在实际项目构建过程中 Tree Shaking 的优化效果往往不尽如人意。而这一问题在 Webpack 5 中得到了不少改善。
(1)Nested Tree Shaking
Webpack 5 增加了对嵌套模块的导出跟踪功能,能够找到那些嵌套在最内层而未被使用的模块属性。例如下面的示例代码,在构建后的结果代码中只包含了引用的内部模块的一个属性,而忽略了不被引用的内部模块和中间模块的其他属性:
1 | // ./src/inner-module.js |
(2)Inner Module Tree Shaking
除了上面对嵌套引用模块的依赖分析优化外,Webpack 5 中还增加了分析模块中导出项与导入项的依赖关系的功能。通过 optimization.innerGraph(生产环境下默认开启)选项,Webpack 5 可以分析特定类型导出项中对导入项的依赖关系,从而找到更多未被使用的导入模块并加以移除。例如下面的示例代码:
1 | //./src/inner-module.js |
在 nested-module.js 中新增了导出项 usingB,该导出项间接依赖导入项 inner.b,而这一导出项在入口模块中并未使用。在默认情况下,构建完成后只保留真正被使用的 inner.a。但是如果将优化项 innerGraph 关闭(且需要同时设置 concatenateModules:false),构建后会发现间接引用的导出项没有被移除,该导出项间接引用的 inner.b 也被保留到了产物代码中。
(3)CommonJS Tree Shaking
Webpack 5 中增加了对一些 CommonJS 风格模块代码的静态分析功功能:
- 支持 exports.xxx、this.exports.xxx、module.exports.xxx 语法的导出分析。
- 支持 object.defineProperty(exports, “xxxx”, …) 语法的导出分析。
- 支持 require(‘xxxx’).xxx 语法的导入分析。
1 | //./src/commonjs-module.js |
可以看到产物代码中只有被引入的属性 a 和 console 语句,而其他两个导出属性 b 和 c 已经在产物中被排除了。
3、Logs
第三个要提到的 Webpack 5 的效率优化点是,它增加了许多内部处理过程的日志,可以通过 stats.logging 来访问。下面两张图是使用相同配置 stats: {logging: "verbose"} 的情况下,Webpack 4 和 Webpack 5 构建输出的日志:
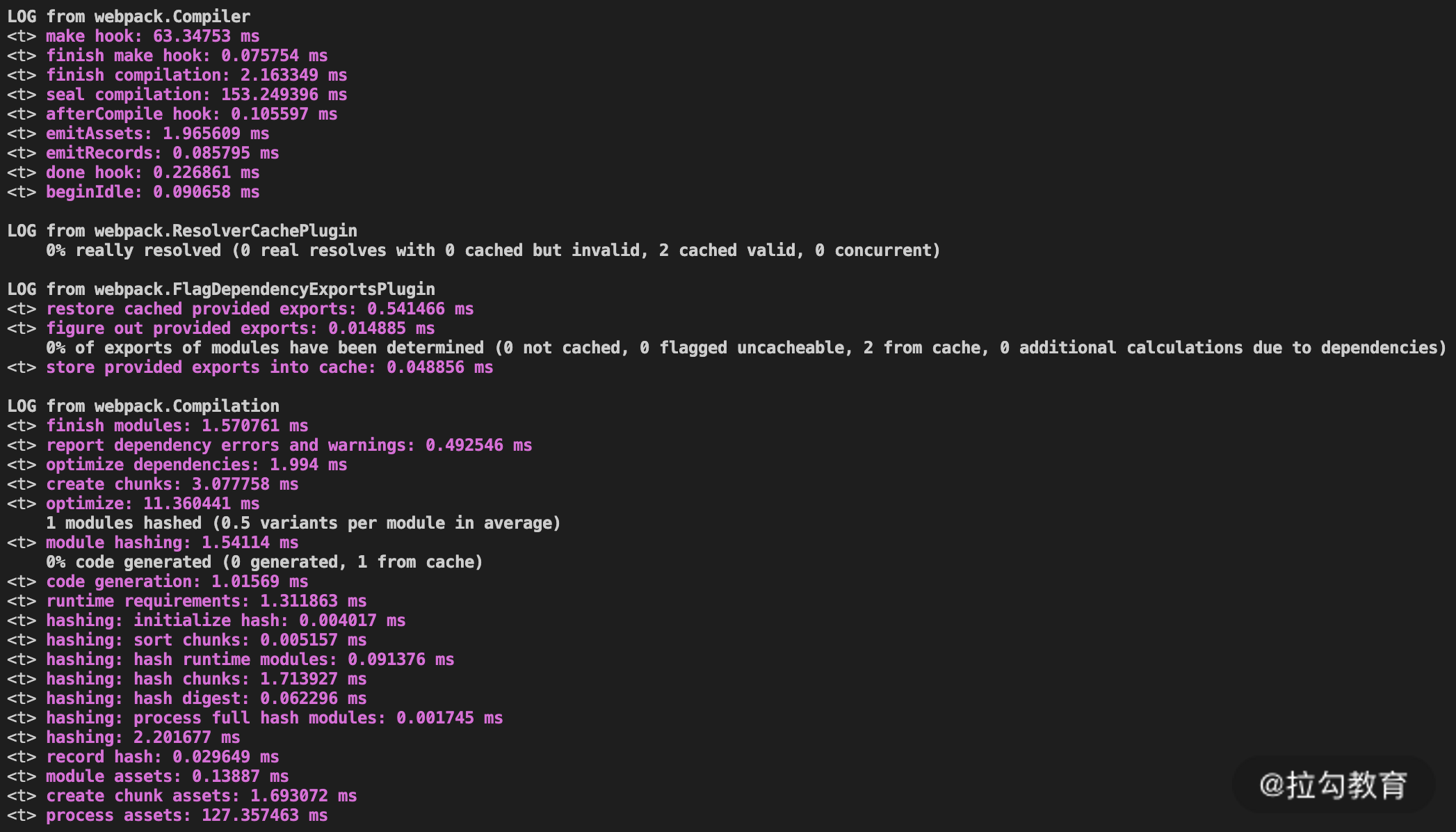
可以看到,Webpack 5 构建输出的日志要丰富完整得多。通过这些日志能够很好地反映构建各阶段的处理过程、耗费时间,以及缓存使用的情况。在大多数情况下,它已经能够代替之前人工编写的统计插件功能。
参考资料
拉勾教育专栏《前端工程化精讲》
极客时间《玩转Webpack》

