尽管有很多关于JavaScript到底是一门面向对象还是基于对象语言的争议,但是无可否认JavaScript中对象扮演着一个举足轻重的关键角色,因此甚至有说法认为“JavaScript中万物皆对象”,当然毫无疑问这个说法是错误的,JavaScript在运行时的数据类型还包括Number、Boolean等基本类型,但是从中我们也可以感受到对象对于JavaScript中的重要意义。从语言的角度上看JavaScript中的对象更像一个字典,字符串作为键名,任意对象可以作为键值,可以通过键名读写键值。但是在V8中实现对象存储时并没有完全采取字典的存储方式,而是采用了一套更为复杂和高效的存储策略。
索引属性(elements)与命名属性(properties)
1 | var a = { 1: "a", 2: "b", "first": 1, 3: "c", "second": 2 } |
在上面这段代码中我们打印出来我们随机设置了属性的对象a和b,但是我们发现控制台打印出来的结果却很有规律,总的来说有以下两点:
- 设置的数字属性最先被打印出来,且按照数字的大小进行了排序
- 设置的字符串属性按照设置时的顺序依次被打印出来
之所以出现这种情况是因为ECMAScript规范中定义了数字属性应该按照索引值大小升序排列,字符串属性按照创建时的顺序升序排列,因此我们将对象中的数字属性称为排序属性,V8中称为elements,字符串属性被称为命名属性,V8中称为properties,我们通过下面示例来查看这两种属性的存取:
1 | function Foo() {} |
我们在控制台执行代码然后查看内存快照:
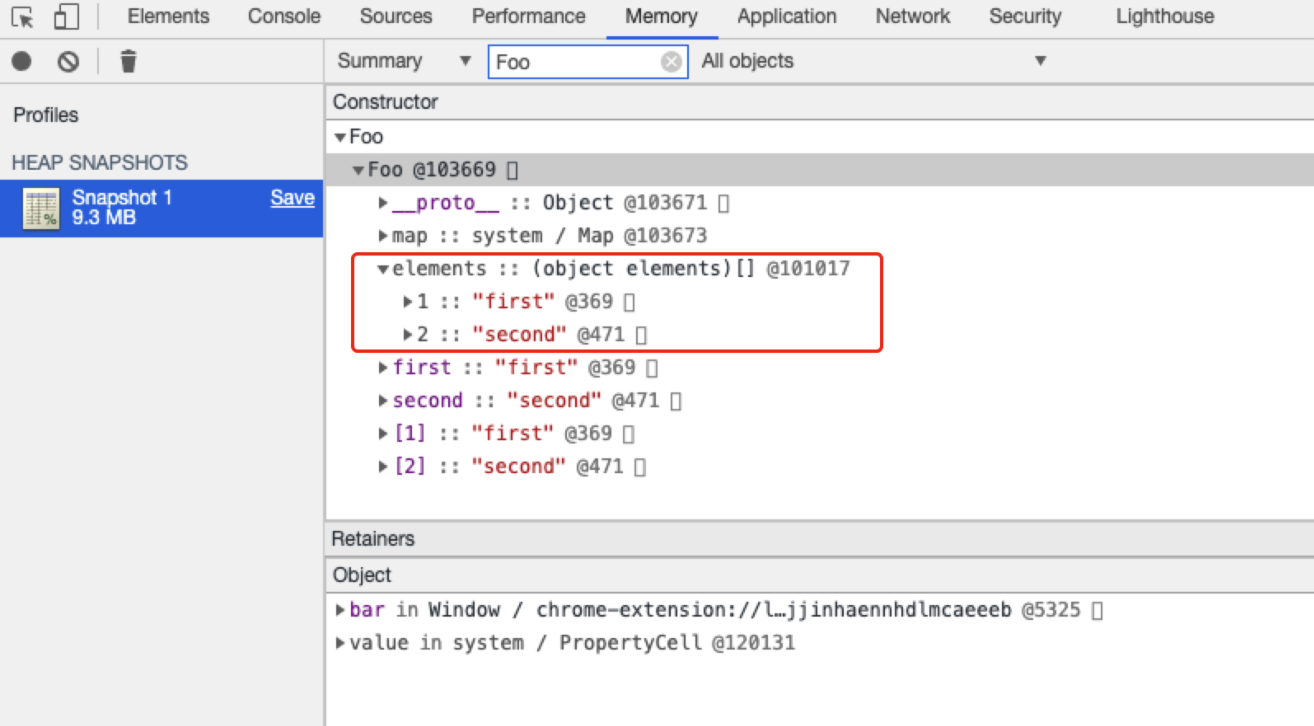
通过上图我们可以发现排序属性被存储在elements属性中,对应elements对象,此时elements对象实际上是一个数组,按照索引顺序存储排序属性,但是当我们添加bar[1111]之后其结构会发生变化:
1 | bar[1111] = 'interesting'; |
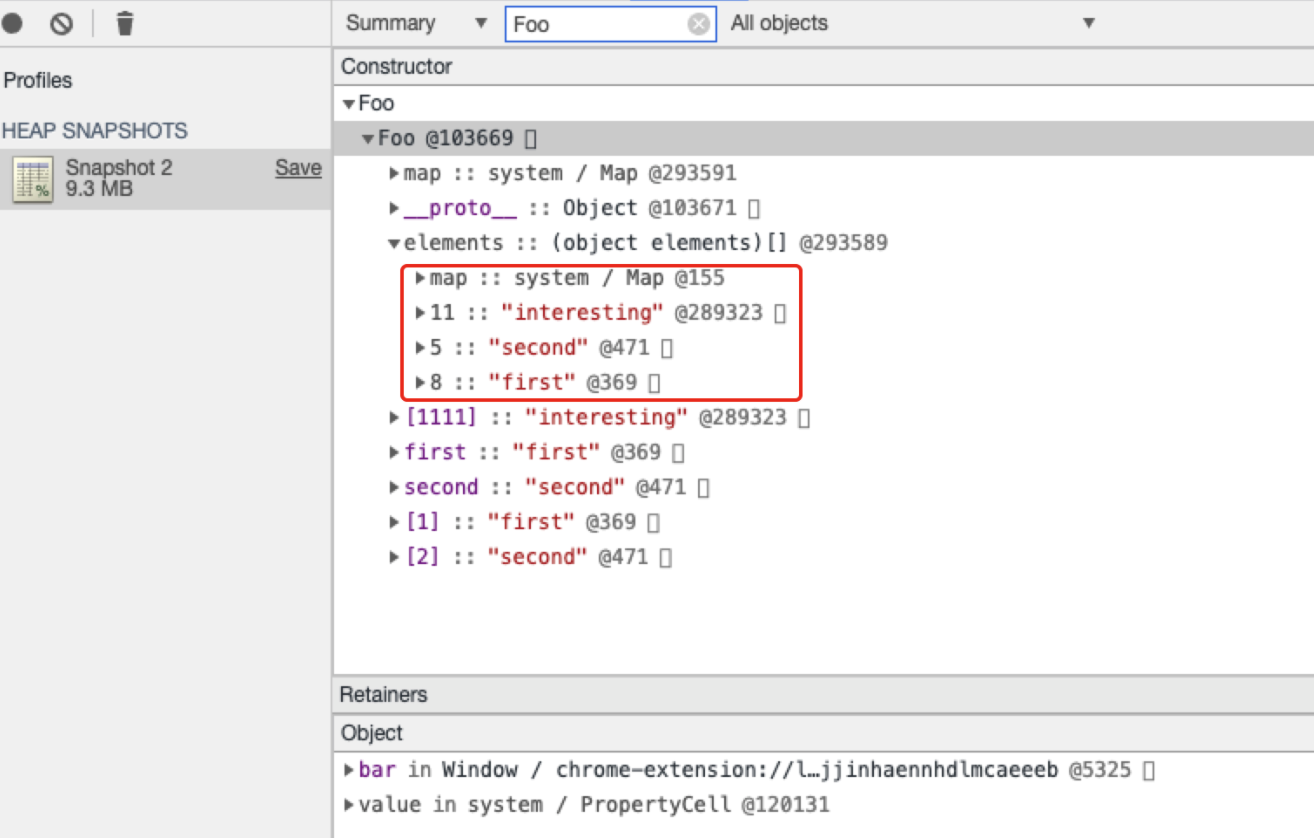
我们发现此时elements对象中的数据存放没有规律了,这是因为当我们添加了a[1111]后数组会变成稀疏数组,为了节省空间,V8会将其转换为哈希存储的方式。
我们注意到在上述的示例的内存快照截图中并没有发现properties属性,相反,命名属性是直接保存在对象内的,这实际上是因为将不同的属性分别保存到elements属性和properties属性会导致我们在查找元素时多了一步查找elements或properties对象的操作,V8因此对命名属性采取了一种更为权衡的策略以加快属性的查找效率,也对应了V8中命名属性的三种不同存储方式:对象内属性、快属性和慢属性。
对象内属性、快属性和慢属性
V8最终对命名属性所采取的策略主要是将部分命名属性直接存储到对象本身,我们将其称为对象内属性(in-object properties),对象内属性由于直接保存在对象本身,相比于快属性和慢属性其少了一次寻址的时间,因此对象内属性是三种存储方式中访问速度最快的。不过对象内属性的数量是由对象的初始大小决定的,如果添加的属性超出那么他们会被分配在properties属性对象的属性存储空间中,虽然多了一层间接层,但是可以自由的扩容,同时我们根据属性存储空间是否为线性存储空间将属性区分为快属性(fast properties)和慢属性(slow properties),我们以如下示例进行说明:
1 | function Foo(num) { |
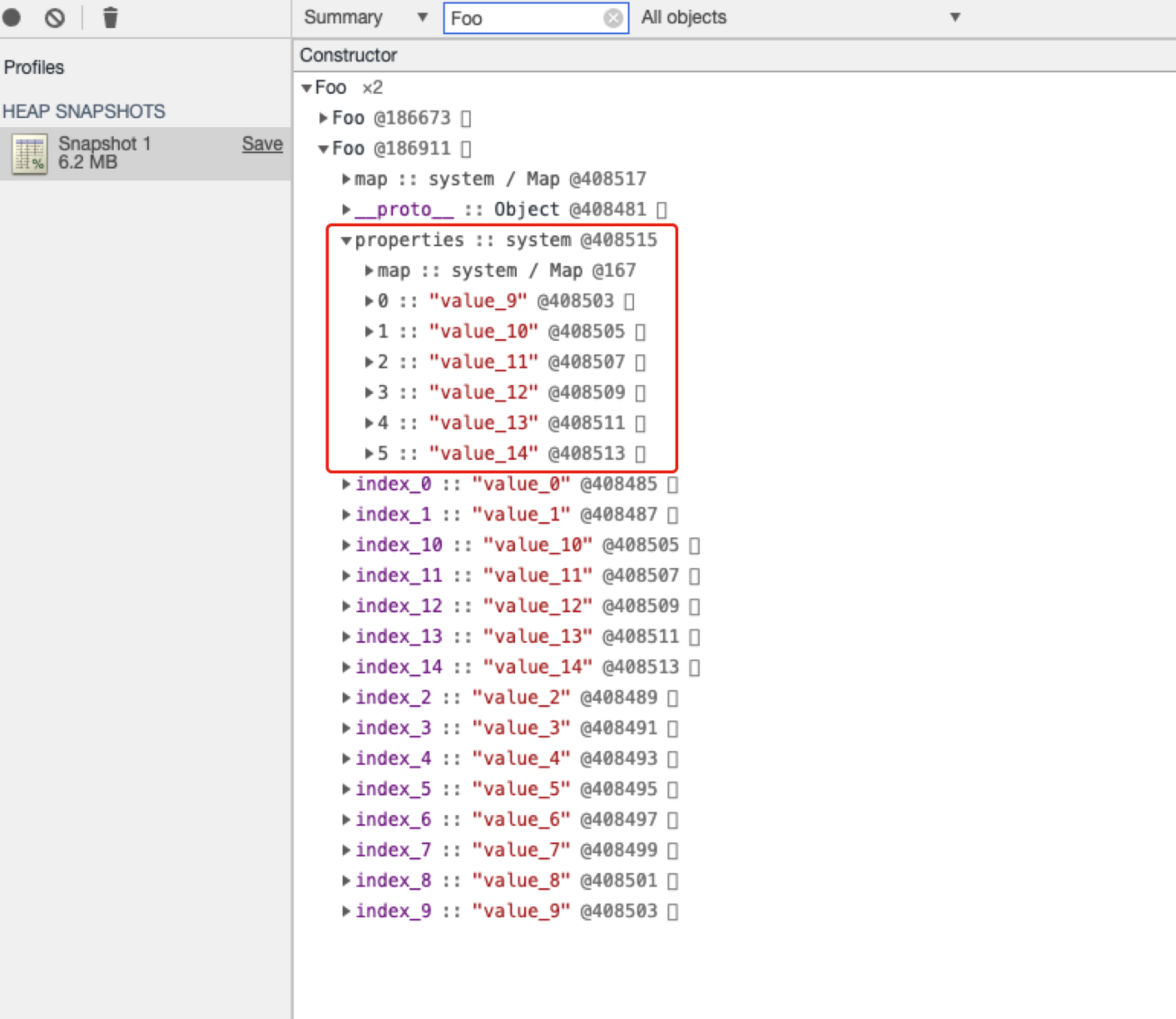
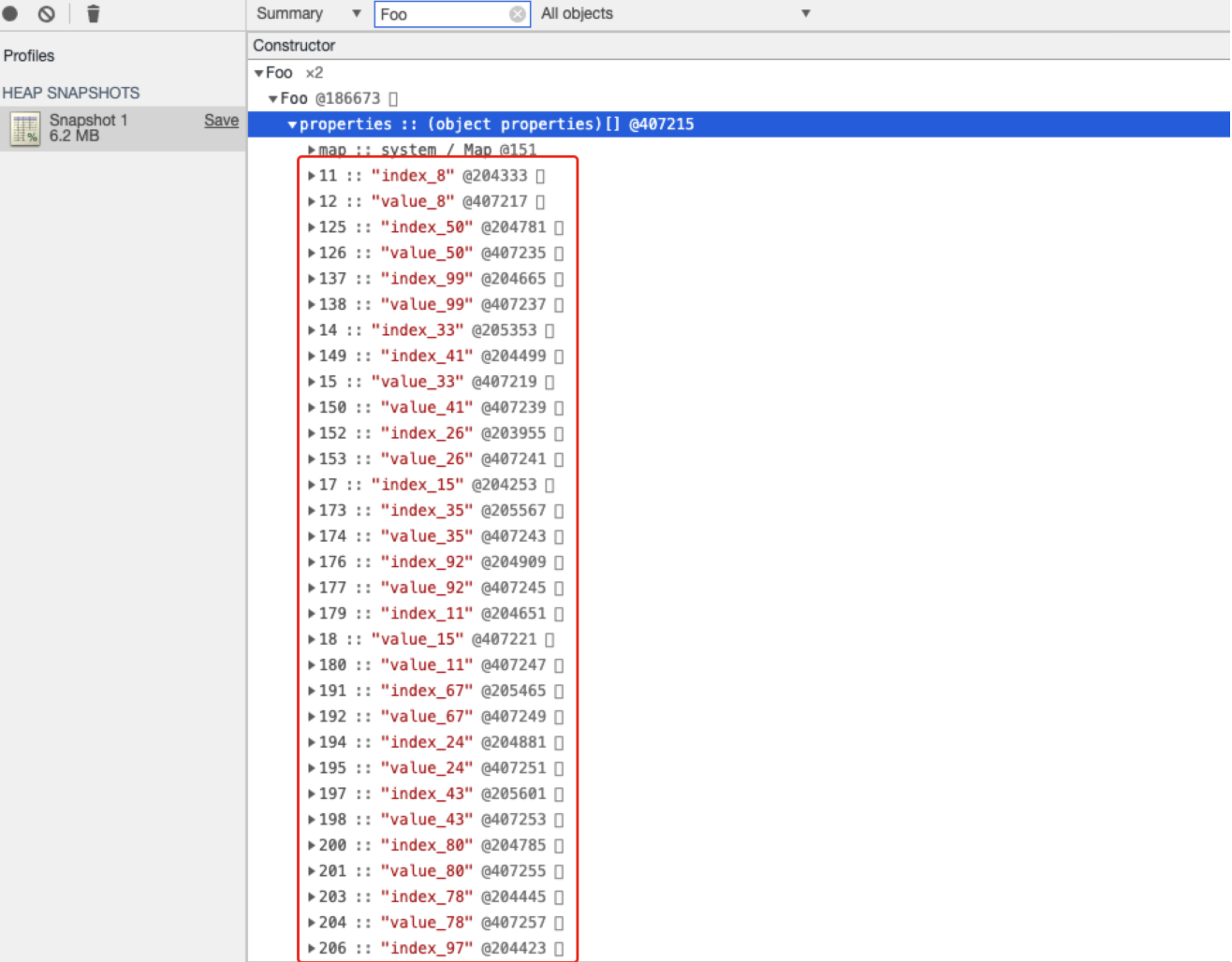
由于创建的命名属性的数目超出了对象内属性的数量,因此其他属性就被保存到了properties中,在bar对象中由于属性数目少,所以properties对象按照设置顺序在线性的数据结构来存储,但是对于baz对象而言属性太多了,因此采用了非线性的字典形式存储,那么V8中为什么要对命名属性的存放区分快属性和慢属性呢?
我们知道所有的数据在底层都会表示为二进制,如果程序逻辑只涉及二进制的位运算(包括与、或、非)速度是最快的,对象内属性和快属性做的事情很简单,线性查找每一个位置是不是指定的位置,这部分的耗时可以简单理解为至多N次简单位运算(N为属性的总数)的耗时,而慢属性则需要先经过哈希算法计算,哈希运算的本身耗时若干倍于简单位运算,另外哈希表是个二维空间,所以我们在通过哈希算法计算出其中一维的坐标后另一维仍需要线性查找,因此当属性少时快属性的存取效率远高于慢属性,但是当属性太多时快属性的提取效率反而低于慢属性,假设我们需要访问第120个属性,那么快属性就需要至多120次简单位运算,而使用慢属性,假设哈希运算的耗时与60次简单位运算相同,但是第二维的线性比较远小于60次的,此时慢属性的提取效率是优于快属性的,因此无论是对象内属性、快属性还是慢属性,V8不同的选择最终都是为了更高的存取效率。
隐藏类
众所周知,JavaScript是一门动态语言,其执行效率要低于静态语言,那么为什么静态语言的执行效率要比动态语言高呢?我们以如下Java代码为例:
1 | class Point { |
Point类的两个实例的存储方式如下图所示:
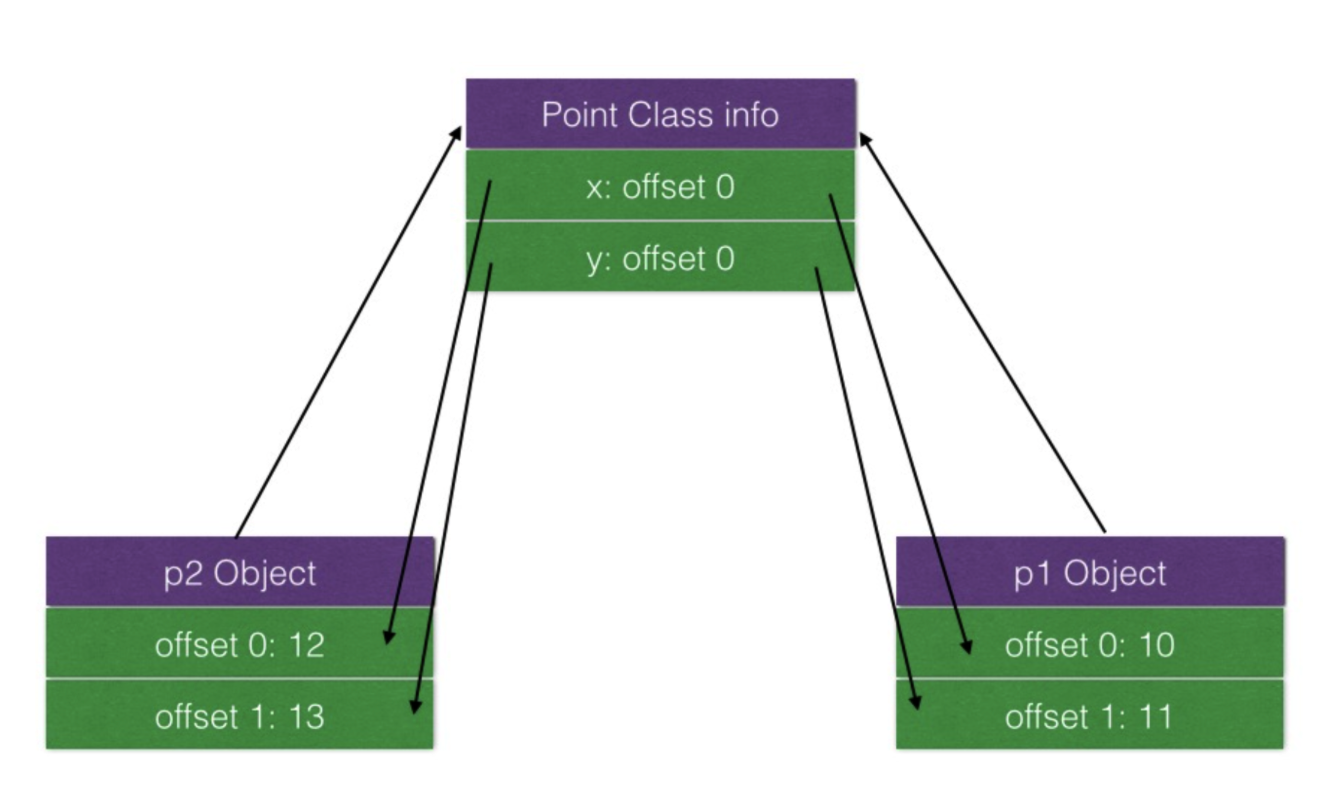
由于Java不是动态脚本,运行时不能为类添加属性,因此Point类的两个实例可以共享Class info,用于保存属性对应值地址偏移量,在获取属性值时可以直接通过偏移量查询来查询对象的属性值,这也就是静态语言的执行效率高的一个原因。V8引擎借鉴了部分静态语言的特性,引入了隐藏类提升对象的属性访问速度。
V8为了能够在属性访问中借鉴静态语言的部分特性首先做了如下两点假设:
- 对象创建好以后不会添加新的属性
- 对象创建好了以后也不会删除属性
基于这两点假设V8引入了隐藏类,v8会在对象初始化时创建一个隐藏类,记录一些该对象的基础布局信息,我们通过如下示例查看对象中的隐藏类:
1 | function Foo() { |
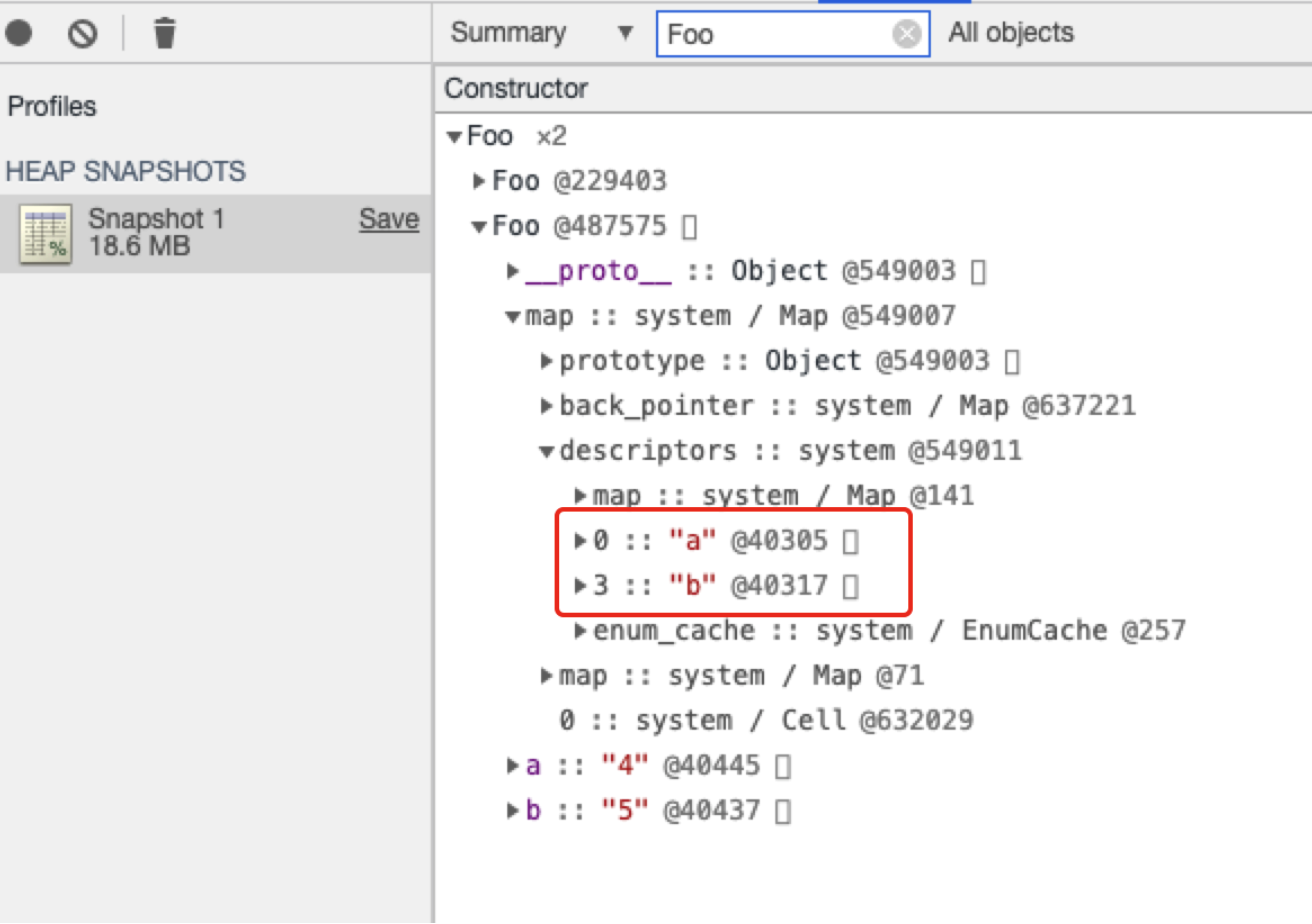
bar对象下的map属性实际上就是bar对象的隐藏类(Chakra 将它们称为Type,JavaScriptCore 称它们为Structure,SpiderMonkey 称他们为Shape,但是更为广泛且规范化的称呼为隐藏类),上图中我们用红线框标注的部分是隐藏类的主要内容,其主要用于保存对象属性的偏移量和属性除了[[value]]以外的其他特征:
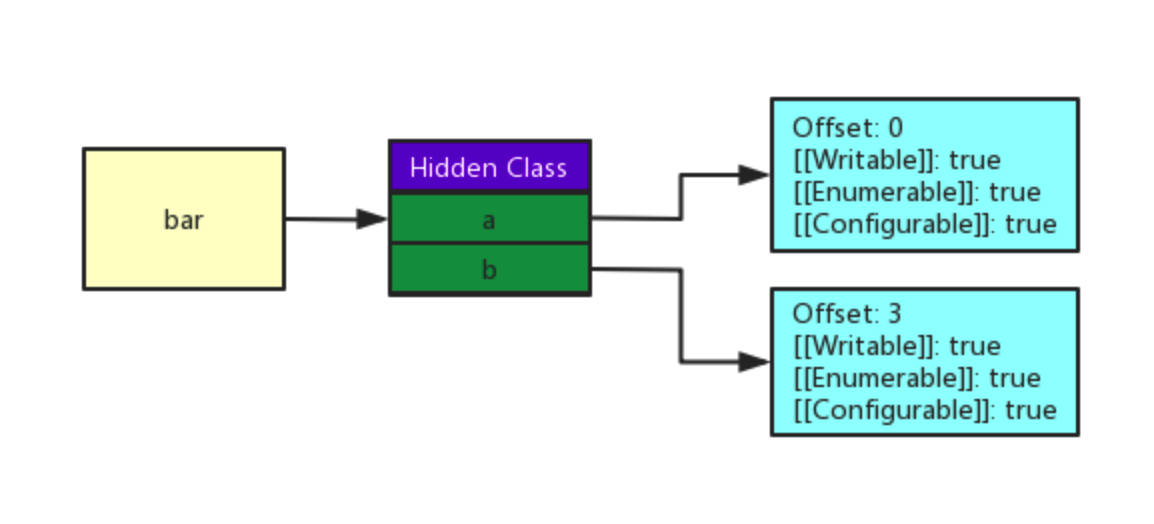
隐藏类的引入将属性的[[value]]与其他Attribute分开,因为一般情况下对象的[[value]]是经常发生变动的,而其他Attribute是几乎不怎么改变的,因此隐藏类中保存其他Attribute大大节省了内存空间。
从上面的描述我们可以看到V8为每个对象配置了隐藏类,主要用于描述该对象的形状,进而将部分静态语言的特性的引入JavaScript对象的提取,不过如果两个对象的形状是相同的,重复创建两个不同的隐藏类来描述其形状其实是根本没有必要的,因此此时V8就会为其使用同一个隐藏类,这样有两个好处:
- 减少了隐藏类的创建次数,也间接加速了代码的执行速度
- 减少了隐藏类的存储空间
那么什么情况下两个对象的形状是相同的,要满足以下两点:
- 相同的属性名称
- 相等的属性个数
我们看如下示例:
1 | function Foo() { |
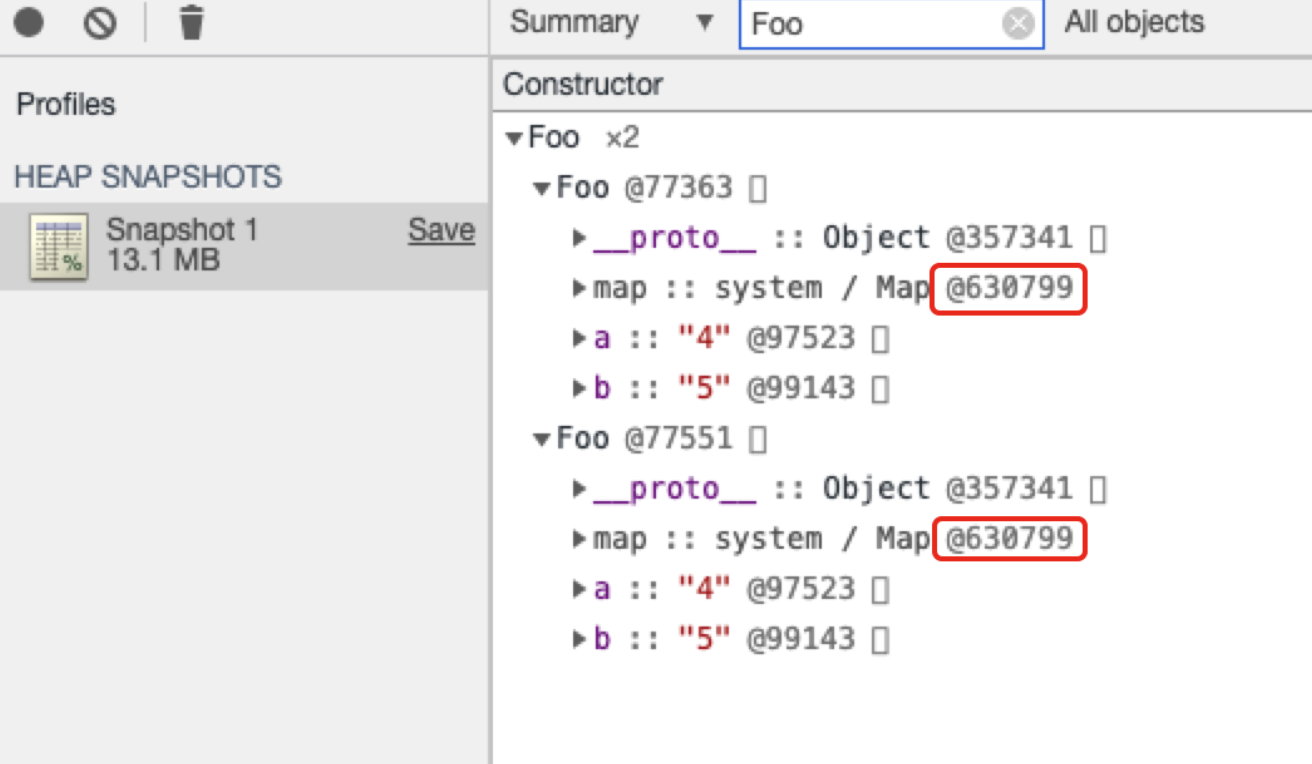
从上图我们可以看到bar对象、baz对象的隐藏类是完全相同的。
在文章前面我们提到V8为了实现隐藏类需要两个假设条件:
- 对象创建好以后就不会添加新的属性
- 对象创建好以后也不会删除属性
但是,JavaScript本质上还是一个动态语言,在执行过程中,对象的形状是随时可变的,对象创建过程中每添加一个命名属性都会生成一个新的隐藏类,而在V8底层为了避免每次新增属性完全新建一个全新的隐藏类,实现了一个将隐藏类连接起来的转换树,具体创建过程如下所示:
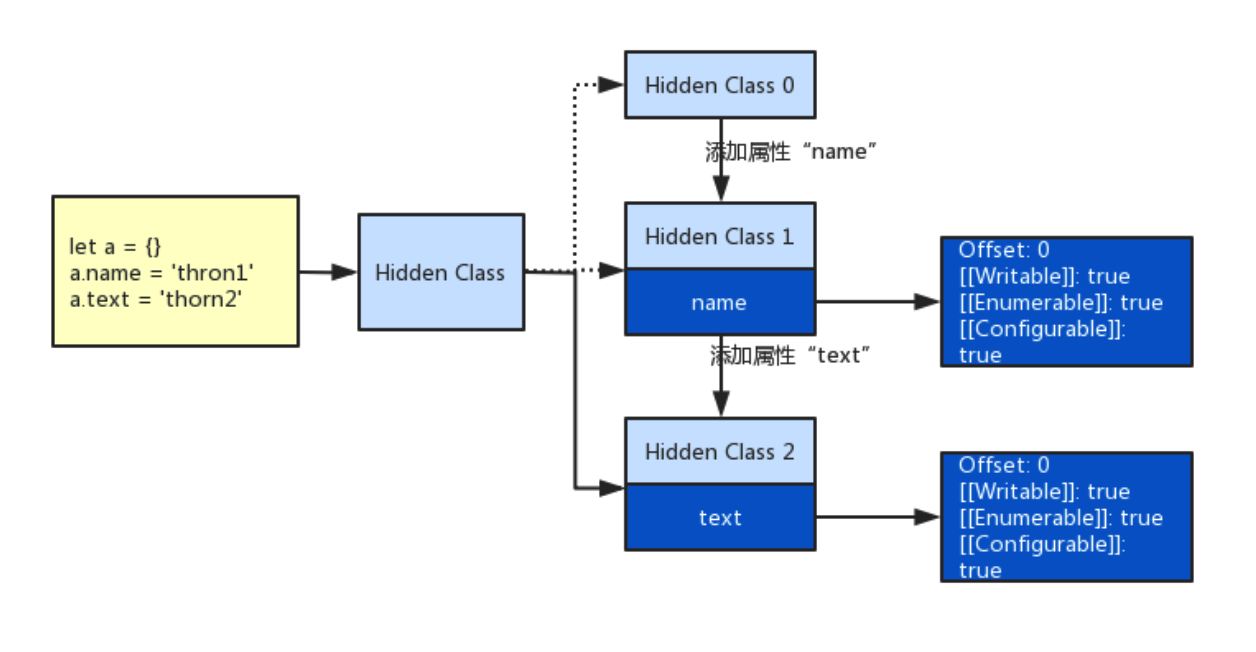
我们通过内存快照可以看到其转换树生成的具体实现:
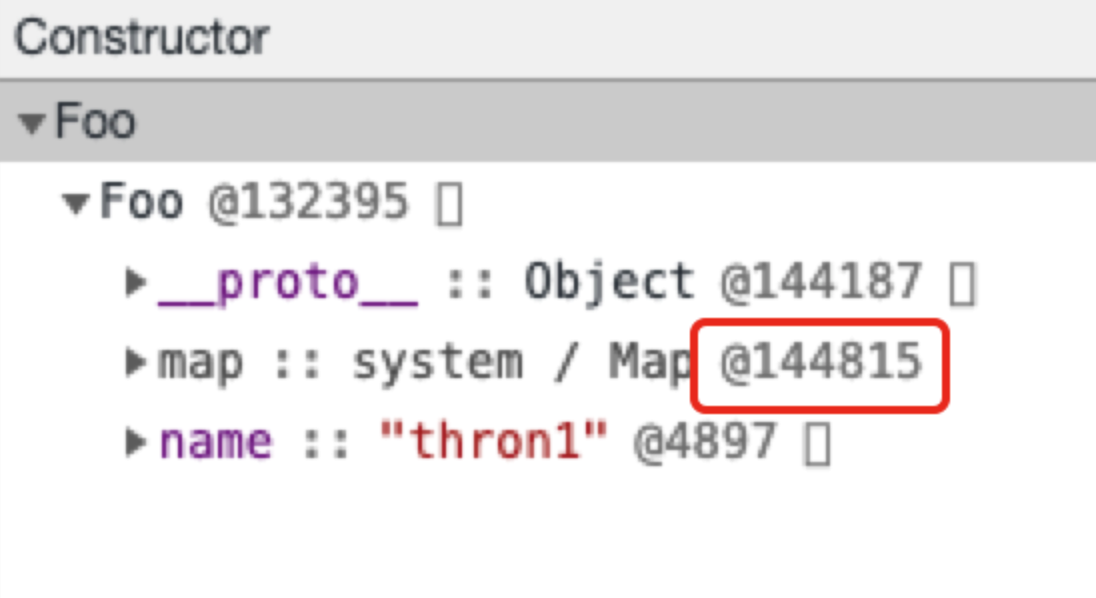
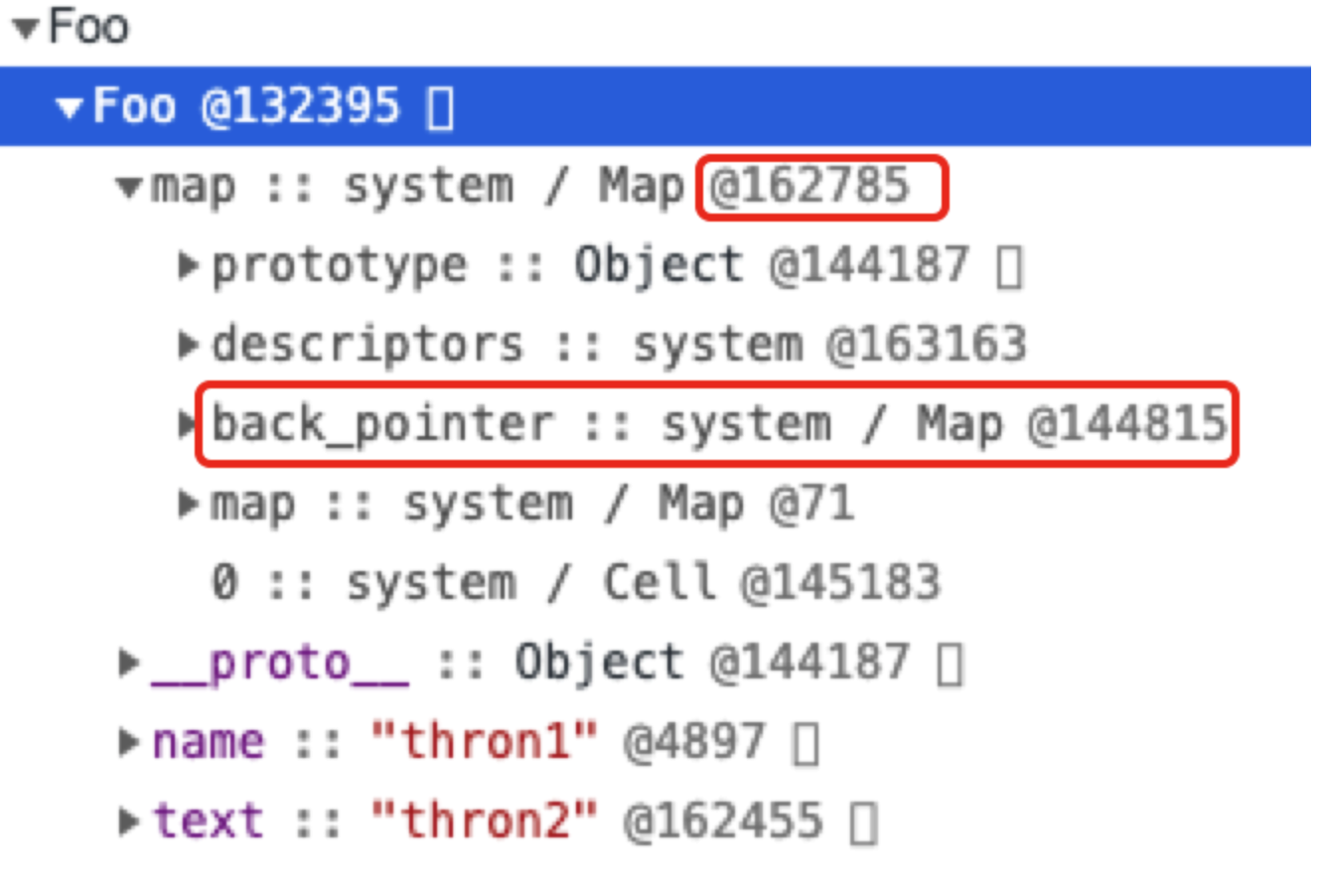
从上图我们可以看出a对象添加了text属性后重新生成了隐藏类,但是新生成隐藏类中的back_pointer属性指向原隐藏类,并以此实现了连接对象所有隐藏类的转换树。
内联缓存(Inline Cache)
1 | function loadX(o) { |
在上述示例中我们定义了一个loadX函数,返回输入对象的x属性,通常V8获取o.x的流程是这样的:查找对象o的隐藏类,再通过隐藏类查找x属性偏移量,然后根据偏移量获取属性值,在这段代码中loadX函数被反复执行,那么获取o.x流程也需要反复执行,因此V8又提出内联缓存(Inline Cache,简称IC)来压缩这个查找过程,以提升对象的查找效率。
内联缓存的原理其实很简单,就是V8执行函数的过程中会观察函数中一些调用点(CallSite)上关键的中间数据,然后把这些数据缓存起来,当下次再次执行该函数的时候V8就可以直接利用这些中间数据,节省了再次获取这些数据的过程,因此V8利用IC可以有效提升一些重复代码的执行效率。其实现的具体过程如下:
IC会为每个函数维护一个反馈向量(FeedBack Vector),反馈向量是一个表结构,由很多项构成,每一项称为一个插槽(Slot),V8在函数执行过程中会将中间数据写入到反馈向量的插槽中,我们以如下示例说明:
1 | function loadX(o) { |
当V8执行到这段函数的时候,它会判断o.y = 4和return o.x 这两段是调用点(Call Site),因为他们使用了对象和属性,因此v8会在loadX函数的反馈向量中为每个调用点分配一个插槽,每个插槽中包括插槽的索引(slot index)、插槽的类型(type)、隐藏类(map)的地址,还有属性的偏移量:
| slot | type | state | map | offset |
|---|---|---|---|---|
| 0 | LOAD | MOND | 34C60824FD61 | 8 |
| 1 | STORE | MOND | 34C60824FD61 | 12 |
| … | … | … | … | … |
| n | … | … | … | … |
观察上图我们可以看出在函数loadX的反馈向量中已经缓存了数据:
- type栏中缓存了操作类型,这里是LOAD(加载)类型,除此之外还有STORE(存储)类型和CALL(函数调用)类型
- state栏中缓存了内联缓存的状态,这里是MONO(单态),除此之外还有POLY(多态)和MAGA(超态)
- map栏中缓存了对象的隐藏类地址,由于示例中的两个调用点都使用了对象o,所以反馈向量两个插槽中的map属性也都是指向同一个隐藏类的,因此这两个插槽的map地址也是一样的
- offset栏缓存了属性的偏移量
这样当V8再次调用loadX函数时,比如执行到loadX函数中的return o.x语句时,它就会在对应的插槽中查找x属性的偏移量,之后v8就能直接去内存中获取o.x的属性值了,这样大大提升了v8执行的效率。
上述示例中内联缓存的状态是单态的,这主要是因为多次执行时对象的形状是固定的,如果对象的形状是不固定的,那么V8会怎么处理呢?我们调整一下上述示例中的代码:
1 | function loadX(o) { |
第一次执行loadX函数时V8会将o的隐藏类记录在反馈向量中,并记录属性x的偏移量,那么当再次调用loadX函数时v8会取出反馈向量中记录的隐藏类,并和新的o1的隐藏类进行比较,发现不是一个隐藏类,此时v8会选择将新的隐藏类也记录在反馈向量中,同时记录属性的偏移量,具体如下图所示:
| slot | type | state | map | offset |
| 0 | LOAD | POLY | 34C60824FD61 | 8 |
| 34C60824FD61 | ||||
| ... | ... | ... | ... | ... |
| n | ... | ... | ... | ... |
当V8再次执行到loadX函数中的o.x语句时,同样会查找反馈向量表,发现第一个槽中记录了两个隐藏类。这时V8会将新的隐藏类和第一个插槽中的两个隐藏类一一比较,如果存在相同的隐藏类则使用该隐藏类的偏移量,如果没有继续将新的隐藏类添加到反馈向量的第一个插槽中,我们根据插槽中隐藏类的数量可以将缓存状态区分为单态(monomorphic,只包含一个隐藏类)、多态(polymorphic,包含2~4个隐藏类)、超态(magamorphic,超过4个隐藏类)。
事实上当状态为单态和多态时V8使用线性结构来保存插槽中的隐藏类,而在超态情形下V8会采取hash表的结构来存储,这无疑会拖慢执行效率,因此我们在代码开发过程中应尽可能避免多态或超态的情况发生。
参考资料:
极客时间《图解Google V8》专栏

