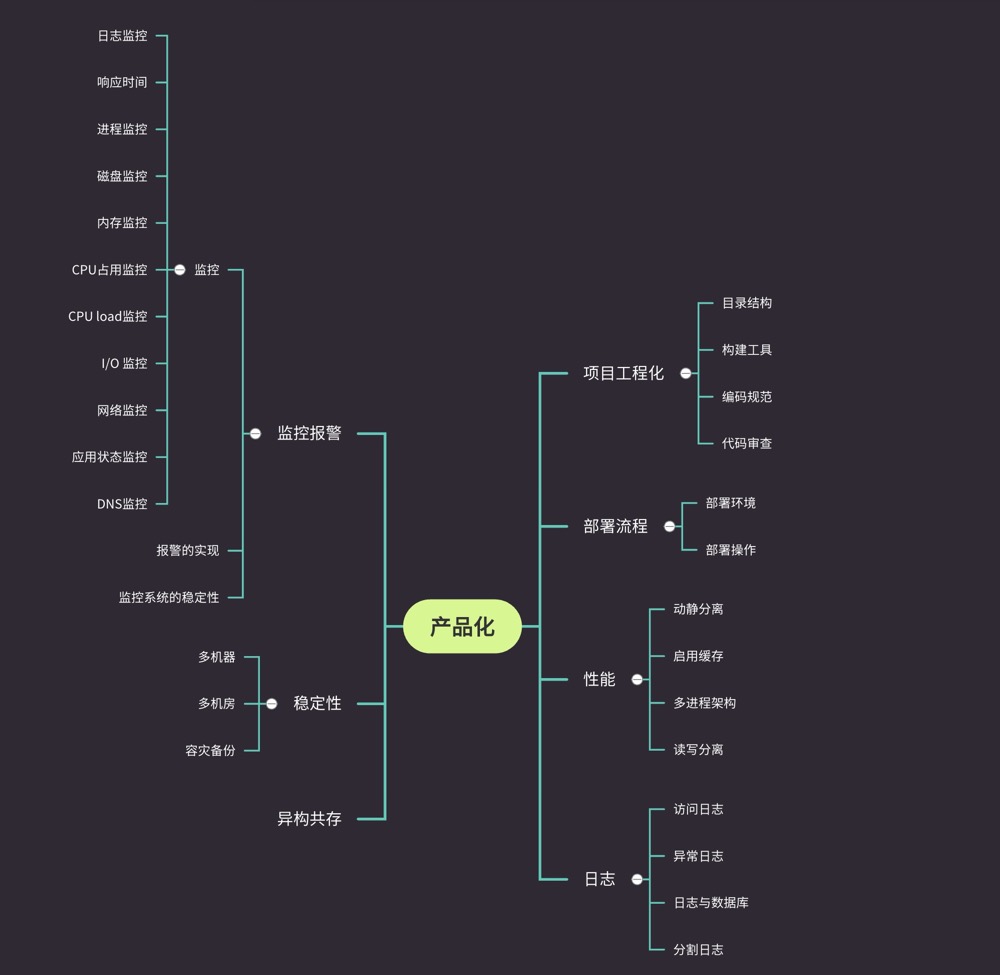
分布式
一、大型网站系统的特点
1、高并发,大流量
需要面对高并发用户,大流量访问。Google 日均 PV 35 亿,日 IP 访问数 3 亿;腾讯 QQ 的最大在线用户数 1.4 亿(2011年数据)。
2、高可用
系统 7 x 24 小时不间断服务。
本文首先会从GraphQL规范讲起,先了解GraphQL语言本身,为什么会有这门语言,以及GraphQL规范中核心定义,然后再去了解GraphQL实现,graphql-js是如何解析,校验,执行GraphQL的。
GraphQL规范是对GraphQL语法的抽象,规范中详细的定义了GraphQL语言的规则,以及GraphQL校验,执行等流程,不同语言的实现都应遵守GraphQL的规范。https://graphql.github.io/graphql-spec/
TCP 全名传输控制协议,在 OSI 模型中属于传输层协议。具体如下图所示:
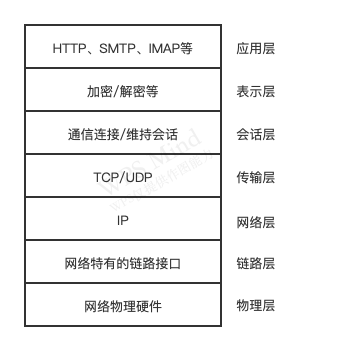
TCP 是面向连接的协议,其显著的特征是在传输之前需要 3 次握手形成会话,只有会话形成后,服务端和客户端之间才能互相发送数据。在创建会话的过程中,服务器端和客户端分别提供一个套接字,这两个套接字共同形成一个连接。服务器端与客户端则通过套接字实现两者之间的连接操作。
我们可以通过 net.createServer(listener) 即可创建一个 TCP 服务器,listener 是连接事件 connection 的侦听器,举个例子:
1 | var net = require("net") |
我们可以利用 Telnet 工具作为客户端与服务器进行会话交流:
1 | telent 127.0.0.1 8124 |
除了端口外我们也可以对 Domain Socket 进行监听:
1 | server.listen('tmp/echo.sock') |
Domain Socket 我们可以通过 nc 工具进行会话测试:
1 | nc -U /tem/echo.sock |
除了使用上述工具外我们还可以自己创建客户端:
1 | var net = require("net") |
执行上述客户端代码文件与使用 Telnet 和 nc 的会话结果别无差别,如果是 Domain Socket 在填写选项时,填写 path 即可:
1 | var client = net.connect({ path: '/tmp/echo.sock' }) |
服务器事件
对于通过 net.createServer() 创建的服务器而言,它是一个 EventEmitter 实例,它的自定义事件有如下几种。
连接事件
服务器可以同时与多个客户端保持连接,每个连接都是典型的可写可读的 Stream 对象,它具有如下自定义事件:
UDP 又称用户数据包协议,提供面向事务的简单不可靠信息传输服务,与 TCP 一样同属于网络传输层。其与 TCP 最大的不同在于 UDP 不是面向连接的。TCP 中连接一旦建立所有的会话都基于连接完成,客户端如果要与另一个服务端通信必须新建一个套接字来完成连接。但在 UDP 中一个套接字可以与多个 UDP 服务通信。
1 | var dgram = require('dgram') |
如上述示例所示,创建 UDP 服务端的核心在于创建 UDP 套接字,UDP 套接字一旦创建既可以作为客户端发送数据,也可以作为服务器端接收数据。想要让 UDP 套接字接收网络信息只需要调用 dgram.bind(port, [address]) 方法对网卡和端口进行绑定即可。
1 | var dgram = require("dgram") |
当使用套接字作为客户端时可以调用 send 方法发送消息到网络中,send 方法的参数如下:
1 | socket.send(buf, offset, length, port, address, [callback]) |
与 TCP 连接的 write 方法相比 send 方法的参数列表要复杂的多,但是它更灵活的地方在于可以随意发送数据到网络中的服务器端。
UDP 的套接字与 TCP 的不同,它只是 EventEmitter 实例,而非 Stream 实例,它具备如下自定义事件:
HTTP 的全称是超文本传输协议,HTTP 构建于 TCP 之上,属于应用层协议。从协议的角度来说现在的应用如浏览器,其实是一个 HTTP 的代理,用户的行为将会转化为 HTTP 报文发送给服务器端。服务器端在处理请求后,发送响应报文给代理,因此 HTTP 服务只做两件事:处理 HTTP 请求和发送 HTTP 响应。
Node 的 http 模块包含了对于 HTTP 处理的封装。在 Node 中 HTTP 服务继承自 TCP 服务器(net 模块),它能够与多个客户端保持连接,由于其采用事件驱动的形式,并不为每一个连接创建额外的线程或进程,保持很低的内存占用,所以能实现高并发。HTTP 服务与 TCP 服务有区别的地方在于,在开启了 keep-alive 之后,一个 TCP 会话可以用于多次请求和响应。TCP 以 connection 为单位进行服务,HTTP 服务以 request 为单位进行服务,http 模块是将 connection 到 request 的过程进行了封装。
除此之外,http 模块将连接所用的套接字读写抽象为 ServerRequest 和 ServerResponse 对象,它们分别对应请求和响应操作。在请求产生的过程中,http 模块拿到连接中传来的数据,调用二进制模块 http_parser 进行解析,在解析完请求报文的报头后,触发 request 事件,调用用户的业务逻辑,流程如下图所示:
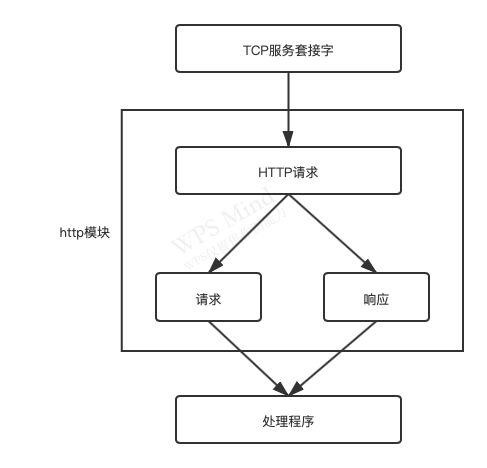
http 请求
对于 TCP 连接的读操作,http 模块将其封装为 ServerRequest 对象。请求报文通过 http_parser 进行解析,报文头被解析为如下部分:
Key: Value 格式,被解析后放置在 req.headers属性上报文体部分则被抽象为一个只读流对象,如果业务逻辑需要读取报文体中的数据,则要在这个数据流结束后才能进行操作,如下所示:
1 | function (req, res) { |
http 响应
HTTP 响应相对简单一些,它封装了对底层连接的写操作,可以将其看成一个可写的流对象。它影响响应报文头部信息的 API 为 res.setHeader() 和 res.writeHeader()。可以调用 setHeader 进行多次设置,但只有调用了 writeHeader 后,报头才会写入到连接中,除此之外,http 模块会自动帮你设置一些头信息,如Date、Connection 等。
报文体部分则是调用 res.write() 和 res.end() 方法实现,后者与前者的区别在于 res.end() 会先调用 write() 发送数据,然后发送信号告知服务器这次响应结束。
http 服务的事件
HTTP 服务器也是 EventEmitter 的实例,实现的自定义事件列表如下所示:
Except:100-continue 的请求到服务器,服务器将会触发 checkContinue 事件;如果没有为服务监听这个事件,服务器将会自动响应客户端 100 Continue 状态码,表示接受数据上传;如果不接受较多的数据时,响应客户端 400 Bad Request 拒绝客户端继续发送数据即可。需要注意的是,当该事件发生时不会触发 request 事件,两个事件之间互斥。当客户端收到 100 Continue 后重新发起请求时,才会触发 request 事件。http 模块提供了一个底层 API:http.request(options, connect) 用于构造 HTTP 客户端,其中 options 参数决定了这个 HTTP 请求头中的内容,它的选项有如下这些:
报文体的内容由请求对象的 write() 方法和 end() 方法实现:通过 write() 方法向连接中写入数据,通过 end() 方法告知报文结束。它与浏览器中的 Ajax 调用几近相同,Ajax 的实质就是一个异步的网络 HTTP 请求。
http 响应
HTTP 客户端的响应对象与服务器端较为类似,在 ClientRequest 对象中,它的事件叫做 response。ClientRequest 在解析响应报文时,一解析完响应头就触发 response 事件,同时传递一个响应对象以供操作 ClientResponse。后续响应报文体以只读流的方式提供。
http 代理
如同服务器端的实现一般,http 提供的 ClientRequest 对象也是基于 TCP 层实现的,在 keep-alive 的情况下,一个底层会话连接可以多次用于请求。为了重用 TCP 连接,http 模块包含一个默认的客户端代理对象 http.globalAgent。它对每个服务器端(host + port)创建的连接进行了管理,默认情况下,通过 ClientRequest 对象对同一个服务器端发起的 HTTP 请求最多可以创建 5 个连接,其实质上就是一个连接池。
我们也可以通过自行构造代理对象来对限制数量进行修改:
1 | var agent = new http.agent({ |
除此之外还可以设置 agent 选项为 false 来脱离连接池的管理,使请求不受并发的限制。
Agent 对象的 sockets 和 requests 属性分别表示当前连接池中使用中的连接数和处于等待状态的请求数,在业务中监视这两个值有助于发现业务状态的繁忙程度。
http 客户端事件
Expect: 100-continue 头信息,以试图发送较大数据量,如果服务器端响应 100 Continue 状态,客户端将触发该事件。WebSocket 协议与 Node 之间的配合堪称完美,主要有两点:
除此之外 WebSocket 相较于 HTTP 还有如下好处:
相比于 HTTP,WebSocket 更接近于传输层协议,它并没有在 HTTP 的基础上模拟服务器端的推送,而是在 TCP 上定义独立的协议,HTTP 协议只是完成了其握手部分。
客户端建立连接时,通过 HTTP 发起请求报文,如下所示:
1 | GET /chat HTTP/1.1 |
与普通的 HTTP 请求协议略有区别的部分在于如下协议头:
1 | Upgrate: websocket |
上述字段表示请求服务器端升级协议为 WebSocket。
Set-WebSocket-Key 的值是随机生成的 Base64 编码的字符串,主要用于安全校验,服务器端接收到之后将其与字符串 “258EAFA5-E914-47DA-95CA-C5AB0DC85B11” 相连形成字符串 “GhlIHNhbXBsZSBub25jZQ==258EAFA5-E914-47DA-95CA-C5AB0DC85B11”,然后通过 sha1 安全散列算法计算出结果后,再进行 Base64 编码,最后返回客户端。
而 Sec-WebScoket-Protocal 和 Sec-WebSocket-Version 字段主要用于指定子协议和版本号。
服务端在处理完请求后响应报文如下所示:
1 | HTTP/1.1 101 Switching Protocols |
上面的报文告知客户端正在更换协议,更新应用层协议为 WebSocket 协议,并在当前的套接字连接上应用新协议。剩余的字段分别表示服务器端基于 Sec-WebSocket-Key 生成的字符串和选中的子协议。客户端将会校验 Sec-WebSocket-Accept 的值,如果成功将开始接下来的传输。
我们以如下代码进行演示:
浏览器端:
1 | var WebSocket = function (url) { |
服务端:
1 | var server = http.createServer(function (req, res) { |
在 WebSocket 协议中,数据传输阶段使用 frame(数据帧)进行通信,frame 分不同的类型,主要有:文本数据,二进制数据。出于安全考虑和避免网络截获,客户端发送的数据帧必须进行掩码处理后才能发送到服务器,不论是否是在 TLS 安全协议上都要进行掩码处理。服务器如果没有收到掩码处理的数据帧时应该关闭连接,发送一个 1002 的状态码。服务器不能将发送到客户端的数据进行掩码处理,如果客户端收到掩码处理的数据帧必须关闭连接。
那我们服务器端接收到的数据帧是怎样的呢?

数据帧
WebSocket 的数据传输是要遵循特定的数据格式-数据帧(frame)
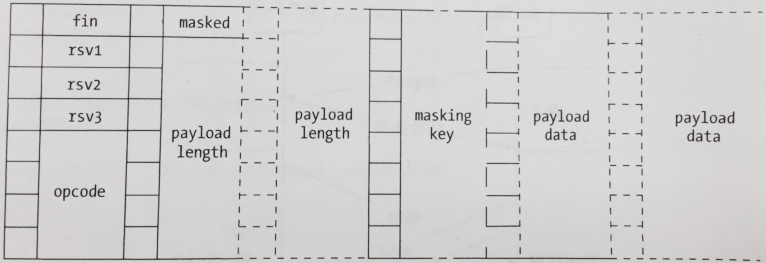
每一列代表一个字节,一个字节8位,每一位又代表一个二进制数。
关于数据帧
因为 WebSocket 服务端接收到的数据有可能是连续的数据帧,一个 message 可能分为多个帧发送。但如果使用 fin 来做消息边界是有问题的。
我发送了一个 27378 个字节的字符串,服务器端共接收到 2 帧,两帧的 fin 都为 1,而且根据规范计算出来的两帧的 payload data 的长度为 27372 少了 6 个字节。这缺少的 6 个字节其实刚好等于 2 个固有字节加上 maskingKey 的4个字节,也就是说第二帧就是一个纯粹的数据帧。这又是怎么回事呢??
从结果推测实现,我们接收到的第 2 帧的数据格式不是帧格式,说明数据没有先分帧(分片)后再发送的。而是将一帧分包后发送的。
分片
分片的主要目的是允许当消息开始但不必缓冲该消息时发送一个未知大小的消息。如果消息不能被分片,那么端点将不得不缓冲整个消息以便在首字节发生之前统计出它的长度。对于分片,服务器或中间件可以选择一个合适大小的缓冲,当缓冲满时,写一个片段到网络。
我们 27378 个字节的消息明显是知道 message 长度,那么就算这个 message 很大,根据规范 1 帧的数据长度理论上是 0 < 数据长度 < 65535 的,这种情况下应该 1 帧搞定,他也只是当做一帧来发送,但是由于传输限制,所以这一个帧(我们收到的像是好几帧一样)会被拆分成几块发送,除了第一块是带有 fin、opcode、masked 等标识符,之后收到的块都是纯粹的数据(也就是第一块的 payload data 的后续部分),这个就是 socket 的将 WebSocket 分好的一帧数据进行了分包发送。那么这种一帧被 socket 分包发送,导致像是分帧(分片)发送的情况(服务器端本应该只就收一帧),在服务器端我暂时还没有想到怎样获取状态来处理。
总结,客户端发送数据,在实现时还是需要手动进行分帧(分片),不然就按照一帧发送,小数据量无所谓;如果是大数据量,就会被 socket 自动分包发送。这个与 WebSocket 协议规范所标榜的自动分帧(分片),存在的差异应该是各个浏览器在对 WebSocket 协议规范的实现上偷工减料所造成的。所以我们看见 socket.io 等插件会有一个客户端接口,应该就是为了重新是实现 WebSocket 协议规范。从原理出发,我们接下来还是以小数据量(单帧)数据传输为例了。
解析数据帧
1 | //dataHandler.js |
组装需要发送的数据帧
1 | // 组装数据帧,发送是不需要掩码加密 |
心跳检测
1 | // 心跳检查 |
关闭连接
客户端直接调用close方法,服务器端可以使用socket.end方法。
HTTP_Parser 在解析请求报文时会将报文头中的请求方法抽取出来设置为 req.method。
HTTP_Parser 将其解析为 req.url。一般而言,完整的 URL 地址是如下这样的:
1 | http://user:pass@host.com:8080/p/a/t/h?query=string#hash |
但是客户端代理(浏览器)会将这个地址解析成报文,将路径和查询报文放在报文第一行,如下所示:
1 | GET /p/a/t/h?query=string HTTP/1.1 |
因此最终得到的 req.url 的值为 ‘/p/a/t/h?query=string’。
查询字符串位于路径之后,形成请求报文首行的第二部分,Node 提供了 querystring 模块用于处理这部分数据。
HTTP 是一个无状态的协议,但现实中的业务却是需要一定的状态的,这就催生了 Cookie 的诞生,客户端发送的 Cookie 在请求报文的 Cookie 字段中,HtTP_Parser 会将所有的报文字段解析到 req.headers 上,Cookie 是 req.headers.cookie。具体内容格式如下所示:
1 | 'csrftoken=HpZuyoYbH_hOQWHUv-0bbb9H; Hm_lvt_f1621cb3fb0792bb294fce1b938d5eef=1632186900; Hm_lpvt_f1621cb3fb0792bb294fce1b938d5eef=1633872461' |
除此之外我们还可以在服务端通过 Set-Cookie 字段设置客户端 Cookie,除了 name=value 是必须包含的部分还有如下几个主要参数配置项:
Session 的数据只保留在服务器端,客户端无法修改,这样数据的安全性得到一定的保障,数据也无须在协议中每次被传递,但是还需要将每个客户和服务器中的数据一一对应起来,这里主要有常见的两种实现方式:
两种方法实现的思路主要是通过 Cookie 携带 Session 的口令或通过请求中的查询字符串来携带。
除此之外我们还需要注意如下亮点:
HTTP 支持的缓存策略主要分为 “强制缓存” 和 “协商缓存”。“强制缓存“ 主要通过 Expires 和 Cache-Control 字段,而 “协商缓存” 主要通过 Last-Modified 和 If-Modified-Since、ETag 和 If-None-Match,更多详情可查看我的博客浏览器缓存。
除了设置缓存之外我们还需要服务端意外更新后通过客户端及时更新的能力,这使得我们在使用缓存时也要为其设定版本号,所幸浏览器是根据 URL 进行缓存,那么一旦内容有更新时,我们就让浏览器发起新的 URL 请求,使得新内容能够被客户端更新。一般的更新机制有如下两种:
Basic 认证是当客户端与服务端进行请求时,允许通过用户名和密码实现的一种身份认证方式。如果一个页面需要 Basic 认证,它会检查请求报文头中的 Authorization 字段的内容,该字段的值由认证方式和加密值构成,如下所示:
1 | Authorization: Basic dXNlcjpwYXNz |
在 Basic 认证中,它会将用户和密码部分组合:username + “:” + password 。然后进行 base64 编码。
Basic 认证虽然经过 Base64 加密后在网络传送,但是这近乎明文十分危险,一般只有在 HTTPS 的情况下才会使用,不过 Basic 认证的支持范围十分广泛,几乎所有的浏览器都支持它。
Node 的 http 模块只对 HTTP 报文的头部进行了解析,然后触发了 request 事件。如果请求中还带有内容部分,内容部分需要用户自行接收和解析。
我们可以通过报头中的 Transfer-Encoding 或 Content-Length 字段判断请求中是否带有内容。
在 HTTP_Parser 解析报头结束后,报文内容部分会通过 data 事件触发,我们只需要以流的方式处理即可,如下所示:
1 | const hasBody = (req) => 'transfer-encoding' in req.headers || 'content-length' in req.headers |
通过 form 标签默认的表单提交请求头中的 Content-Type 字段值为 application/x-www-form-urlencoded,而它的报文体内容与查询字符串相同:foo=bar&baz=val,因此它的解析非常容易:
1 | const handle = (req, res) => { |
除了表单数据外常见的提交还有 JSON 和 XML 文件等,判断它们的方式也是通过 Content-Type 字段,值分别为 application/json 和 application/xml。
json 文件的解析是非常简单的,我们可以直接通过 JSON.parse 方法进行解析,XML 文件的解析稍微复杂一些但我们也可以采用 XML 文件到 JSON 对象转换的库,例如 xml2js 模块。
通常的表单,其内容可以通过 urlencoded 的方式编码内容形成报文体,再发送给服务器端,但是业务场景往往需要用户直接提交文件。在前端 HTML 代码中,特殊表单与普通表单的差异在于该表单中可以含有 file 类型的控件,以及需要指定表单属性 enctype 为 multipart/form-data,如下所示:
1 | <form action="/upload" method="post" enctype="multipart/form-data"> |
浏览器在遇到 multipart/form-data 表单提交时,构造的请求报文与普通报文完全不同。首先它的报头中最为特殊的如下所示:
1 | Content-Type: multipart/form-data; boundary=AaB03x |
它代表本次提交的内容是由多部分构成的,其中 boundary=AaB03x 是随机生成的一段字符串,制定每部分内容的分界符。报文的内容将通过在它前面添加 ‘–’ 进行分割,报文结束在它前后都加 ‘–’ 表示结束。另外 Content-Length 的值必须确保是报文体的长度。
在知晓了报问题是如何构成之后解析就变得非常容易,但是对于未知大小的数据量进行处理时依然需要小心,我们也可以采用一些第三方库比如 formidable 来协助我们处理。
内存限制
在我们通过 Node 解析表单、JSON 和 XML 部分时我们采取的策略往往是先保存用户提交的所有数据,然后再解析处理,最后再传递给业务逻辑。这种策略潜在的问题是它仅仅适合数据量小的提交请求,一旦数据量过大将发生内存被占光的情景。
要解决这个问题主要有两种方案:
CSRF
服务器端与客户端通常通过 Cookie 来标识和认证用户,但是部分情况下会出现通过引诱用户点击恶意网站的链接来冒充用户的信息,除了通过配置 Cookie 的相关属性外我们还可以通过添加随机值的方式来解决。也就是说为每个请求的用户,在 Session 中赋予一个随机值,由于该值是一个随机值,攻击者构造出相同随机值的难度相当大,我们只需要在接收端做一次校验就能轻易地识别出该请求是否为伪造的。
对于不同的业务我们希望有不同的处理方式,这就带来了路由的选择问题。
静态文件
这种路由的处理方式十分简单,将请求路径对应的文件发送到客户端即可。
动态文件
这种方式的实现原理是 Web 服务器根据 URL 路径找到对应的文件,如 index.asp。Web 服务器根据文件名的后缀去寻找脚本的解析器,并传入 HTTP 请求的上下文。
现今大多数服务器都能很智能地根据后缀同时服务动态文件和静态文件。但这种方式在 Node 中不太常见,主要原因是文件的后缀都是 js,分不清是后端脚本还是前端脚本。而且 Node 中 Web 服务器与应用业务脚本是一体的,也无须按照这种方式实现。
MVC 模型的主要思想是将业务逻辑按职责分离,主要分为以下几种:
这是目前最经典的封层模式,其工作模式如下:
这里如何根据 URL 做路由映射主要有两种方法实现,一种是通过手工关联映射,一种是自然关联映射。前者会有一个对应的路由文件来将 URL 映射到对应的控制器,后者没有这样的文件。
手工映射主要是通过一个路由文件来将 URL 映射到对应的控制器,其对 URL 的要求十分灵活。不过这种映射关系的解析需要两大基本能力:正则匹配与参数解析,用于对 URL 中的携带参数进行提取与处理。
相较于手工关联,自然关联采用了按照一种约定的方式自然而然地实现路由而无须去维护路由映射文件的手段,例如我们可以对;路径进行如下的划分处理:
/controller/action/pararm1/param2/param3
以 ‘/user/setting/12/1987’ 为例,它会按照约定去找 controllers 目录下的 user 文件,将其 require 出来后,调用这个模块的 setting() 方法,而其余的值作为参数直接传递给这个方法。
总而言之,手工映射对 URL 的处理十分灵活,不过需要我们维护一份路由关系映射文件,而且依赖于正则匹配与参数解析的核心能力。而自然映射的设计十分简洁,但是如果 URL 变动,它的文件也需要发生变动,手工映射只需要改动路由映射即可。
REST 的全称是 Representational State Transfer,中文含义是表现层状态转化。符合 REST 规范的设计,我们称为 RESTful 的设计。它的设计哲学主要是将服务端提供的内容实体看作是一个资源,并表现在 URL 上,然后通过请求方法定义资源的操作,通过 Accept 决定资源的表现形式。
RESTful 与 MVC 的设计并不冲突,而且是更好的改进。相比 MVC,RESTful 只是将 HTTP 请求方法也加入了路由的过程,以及在 URL 的路径上体现得更资源化。
中间件的主要用于简化和隔离基础设施与业务逻辑之间的细节,让开发者能够关注在业务的开发上,以达到提升开发效率的目的。
Node 的 http 模块提供了应用层协议网络的封装,对具体业务并没有支持,因此通过中间件搭建开发框架对业务提供强力支撑是很有必要的。
中间件的编写需要注意如下两个点:
编写高效的中间件其实就是提升单个单元的处理速度,以尽早调用 next() 执行后续逻辑。由于中间件一旦被匹配,那么每个请求都会使该中间件执行一次,哪怕它只浪费1毫秒的执行时间,都会让我们的 QPS 显著下降。常见的优化方法主要有:
在拥有了一堆高效的中间件后我们还需要对每个中间件的合理使用做出判断,避免中间件参与不必要的请求处理处理过程。
服务端的响应从一定程度上决定或指示了客户端该如何处理响应的内容。因此响应包头中的 Content-* 字段十分重要。
MIME
不同的文件类型有不同的 MIME 值,响应在在 Content-Type 字段中返回以便客户端进行对应的处理。
除了 MIME 值外,Content-Type 还可以包括一些参数,比如字符集。
附件下载
Content-Disposition 字段决定了客户端将相应报文数据当作即时浏览的内容,还是可下载的附件。当数据可以存为附件时,它的值为 attachemnt,如果只需即时查看时它的值为 inline。
除此之外 Content-Disposition 字段还能通过参数指定保存时应该使用的文件名。例如:
Content-Disposition: attachment; filename="filename.ext"
响应JSON
我们可以通过指定 Content-Type 字段为 ‘application/json’ 快捷响应 JSON。
响应跳转
我们可以返回 302 状态码同时响应头添加 Location 字段来将用户跳转到别的 URL。
Web 应用最终呈现出来的内容都是通过一系列的视图渲染呈现出来的,在动态页面技术中,最终视图是由模板和数据共同生成出来的。
模板是带有特殊标签的 HTML 字段,通过与数据的渲染,将数据填充到这些特殊的标签中,最后生成普通的带数据的 HTML 片段。
模板技术的实质上就是将模板文件和数据通过模版引擎生成最终的 HTML 代码,形成模板技术主要包括如下四个要素:
模板引擎的实现主要分为如下几个步骤:
模板编译
为了能够最终与数据一起执行生成字符串,我们需要将原始的模板字符串转换成一个函数对象,这个过程称为模板编译。
1 | var compile = function (str) { |
为了让模板引擎更加灵活,字符串能继续表达为字符串,变量能够自动寻找属于它的对象,我们需要引入关键字 with。
1 | var compile = function (str, data) { |
模板安全
实际上 XSS 漏洞的产生大多数跟模板有关,如果数据传入的值为恶意字符串比如 <script>slert("I am XSS")</script> 那么页面就会执行这个脚本。因此为了安全性,大多数模板都提供了转义的功能。转义就是将能形成 HTML 标签的字符转换成安全的字符,转义函数如下:
1 | var excape = function (html) { |
为了让转义与非转义表现得更方便,我们可以使用不同的标签来表示:
1 | var render = function (str, data) { |
为了让模板更强大一些我们为它添加逻辑代码
1 | var compile = function (str) { |
结合我们之前实现的 compile() 与 render() 方法我们已经能够实现将输入的模板字符串进行编译替换的功能,但是通过模板编译生成的中间函数只与模板字符串相关,与具体的数据无关,因此我们可以采用模板预编译的方法,预编译缓存模板编译后的结果,以此实现一次编译多次执行。这里我们再集成文件系统:
1 | var cache = {} |
与文件系统集成后再引入缓存就可以很好的解决性能问题,接口也得到大大简化。
有的时候模板太大太过复杂,会增加维护上的困难,这就导致了子模板的诞生,子模板可以嵌套在别的模板中,多个模板可以嵌入同一个子模板中。我们可以采用 include 关键字实现模板的嵌套:
1 | var files = {}; |
我们在 compile() 方法对字符串解析前先调用 preCompile 方法对数据进行预编译即可实现对子模板的支持。
Bigpipe 是一个需要前后端配合实现的优化技术,它的主要思路是将页面分割成多个部分,先向用户输出没有数据的布局(框架),将每个部分逐步输出到前端,并最终渲染填充框架,完成整个网页的渲染,这个过程中需要前端 JavaScript 的参与,它负责将后续输出的数据渲染到页面上。
它比较重要的有如下几个点:
Node 的多进程采用了著名的 Master-Worker 模式,即主从模式,主从模式是典型的分布式架构中用于并行处理业务的模式具备较好的可伸缩性和稳定性。主进程不负责具体的业务逻辑,而是负责调度或管理工作进程,工作进程负责具体的业务处理。
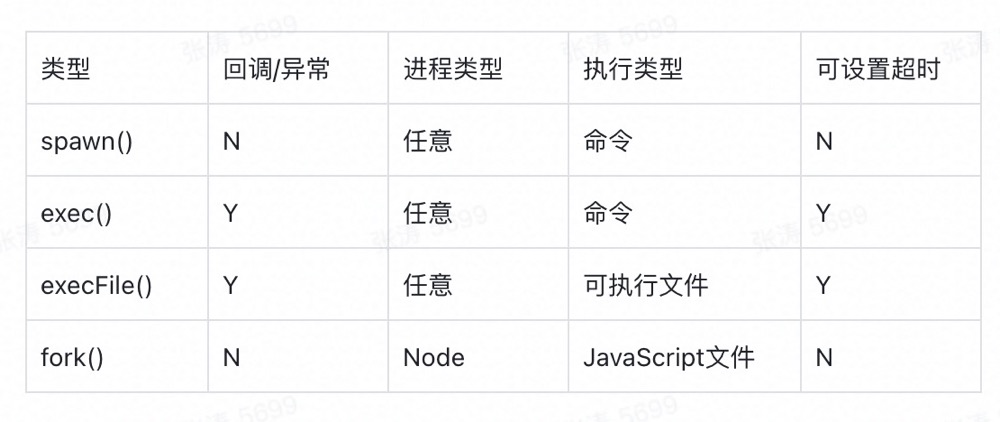
child_process 模块给予了 Node 创建子进程的能力,它提供了 4 个方法用于创建子进程:
注:
举个🌰:
1 | var cp = require('child_process') |
在主从模式中要实现主进程管理和调度工作进程的功能,需要主进程和工作进程之间的通信,进程间通信简称 IPC(Inter-Process Communication),其主要目的是为了让不同的进程能够相互的访问资源并进行协调工作。实现进程间通信的技术有很多,如命名管道、匿名管道、socket、信号量、共享内存、消息队列、Domain Socket等。Node 中实现 IPC 通道的方式如下所示:
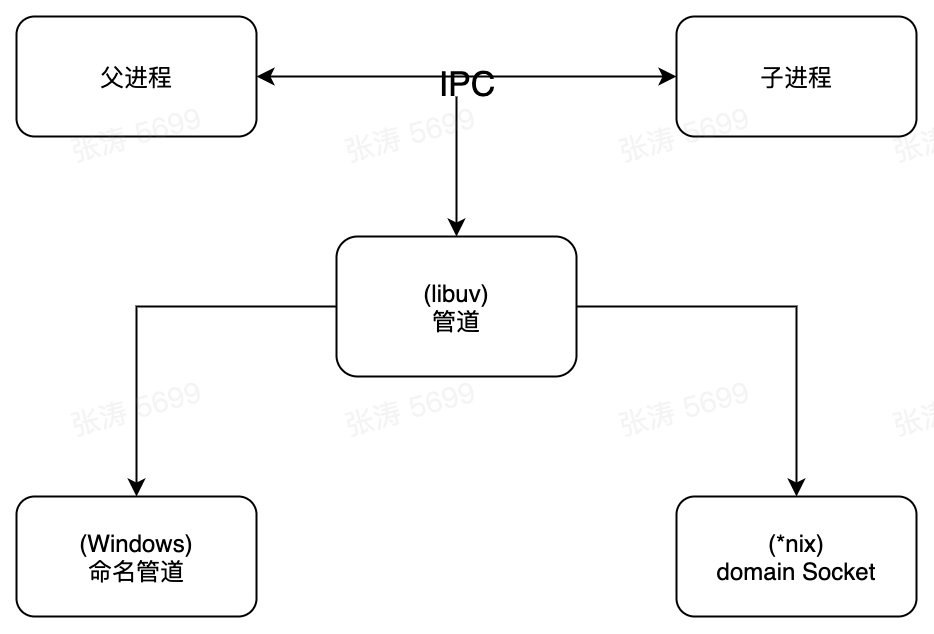
Node 中 IPC 通道的具体细节实现由 libuv 提供,在 Windows 下由命名管道实现 (named pipe) 实现,*nix 系统则采用 Unix Domain Socket 实现。表现在应用层上的进程间通信只有简单的 message 事件和 send 方法,接口十分简洁和消息化。举个🌰:
1 | // parent.js |
那么 Node 创建 IPC 通道的具体实现是怎么样的呢?
父进程在实际创建子进程之前会创建 IPC 通道(在 Node 中 IPC 通道被抽象为 Stream 对象)并监听它,然后才真正创建出子进程,并通过环境变量 (Node_CHANNEL_FD) 告诉子进程这个 IPC 通道的文件描述符。子进程在启动的过程中,根据文件描述符去连接这个已存在的 IPC 通道,从而完成父子进程之间的连接。
注:只有启动的子进程是 Node 进程时,子进程才会根据环境变量去连接 IPC 通道,对于其他类型的子进程则无法实现进程间通信,除非其他进程也按约定去连接这个创建好的 IPC 通道。
为了解决多个工作进程一个端口的问题通常的做法是代理模式,即主进程监听主端口、对外接收所有的网络请求,再将这些请求分别代理到不同的端口的进程上。其优点在于避免了端口不能重复监听的问题,而且我们可以在代理进程上做适当的负载均衡,但是由于进程每接收到一个连接将会用掉一个文件描述符,因此这种代理模式需要浪费一倍数量的文件描述符,这极大的影响了系统的扩展能力。
为了解决这个问题 Node 在版本 v0.5.9 引入了进程间发送句柄的功能。首先什么是句柄?
句柄是一种可以用来标识资源的引用,它的内部包含了指向对象的文件描述符,因此句柄可以用来标识一个服务器端 socket 对象、一个客户端 socket 对象、一个套接字等。
接下来我们通过发送句柄来实现多进程监听同端口
1 | // parent.js |
那么我们为什么可以通过发送句柄来实现多进程监听同一端口呢?句柄发送的具体过程是什么样的呢?
目前子进程对象 send() 方法可以发送的句柄类型包括如下几种:
send() 方法在将消息发送到 IPC 管道前,将消息组装成两个对象,一个参数是 handle,另一个是 message。message 的参数如下所示:
1 | { |
这儿的文件描述符 handle 实际上是一个整数值,而这个 message 对象在写入到 IPC 通道时也会通过 JSON.stringify() 进行序列化。所以最终发送到 IPC 通道中的信息都是字符串,send() 方法能发送消息和句柄并不意味着它能发送任意对象。
连接了 IPC 通道的子进程可以读取到父进程发送的消息,将字符串通过 JSON.parse() 解析还原为对象后,才触发 message 事件将消息传递给应用层使用。在这个过程中消息对象还要被进行过滤处理,message.cmd 的值如果以 NODE_ 为前缀,它将响应一个内部事件 internalMessage。如果 message.cmd 的值为 NODE_HANDLE,它将取出 message.type 值和得到的文件描述符一起还原出一个对应的对象,以 TCP 服务器句柄为例:
1 | function (message, handle, emit) { |
上面的示例中,子进程根据 message.type 创建对应 TCP 服务器对象,然后监听到文件描述符上。
我们独立启动的进程中 TCP 服务器端 socket 套接字的文件描述符并不相同,这也是导致监听相同端口时抛出异常的主要原因,但是对于 send() 发送的句柄还原出来的服务而言,它们的文件描述符是相同的,所以监听相同端口不会引起异常。

在有了父子进程之间的相关事件之后,我们就可以在这些关系之间创建出需要的机制了,比如我们可以当监听到子进程退出后重新启动一个工作进程来继续服务。
1 | // master.js |
自杀信号
上述代码的问题是要等到已有的所有连接断开后进程才退出,在极端的情况下,所有工作进程都停止接收新的连接,所有工作进程都停止接收新的连接,全处在等待退出的状态,但在等到进程完全退出才重启的过程中,所有新来的请求可能存在没有工作进程为新用户服务的情景,因此一个重要的优化手段就是自杀信号。
自杀信号的具体实现是工作进程在得知要退出时向主进程发送一个自杀信号,然后才停止接收新的连接,当所有连接断开后才退出。主进程在接收到自杀信号后,立即创建新的工作进程服务。这样可以大大提高应用的稳定性和健壮性。
除此之外我们的连接很有可能是长连接而不是 HTTP 服务的这种短连接,等待长连接断开可能需要较久的时间,因此为退出设置一个超时时间是有必要的,至此最终优化代码如下所示:
1 | // master.js |
限量重启
在通过自杀信号告知主进程可以使得新连接总是有进程服务,但是工作进程不能无限制地被重启,因为这种无意义的重启已经不符合预期的设置,极有可能是程序编写的错误。因此更好的解决方案是限量重启。
1 | // 重启次数 |
giveup 事件是比 uncaughtException 更严重的异常事件。uncaughtException 只代表集群中某个工作进程退出,在整体保证下,不会出现用户得不到服务的情况,但是这个 giveup 事件则表示集群中没有任何进程服务了,十分危险。
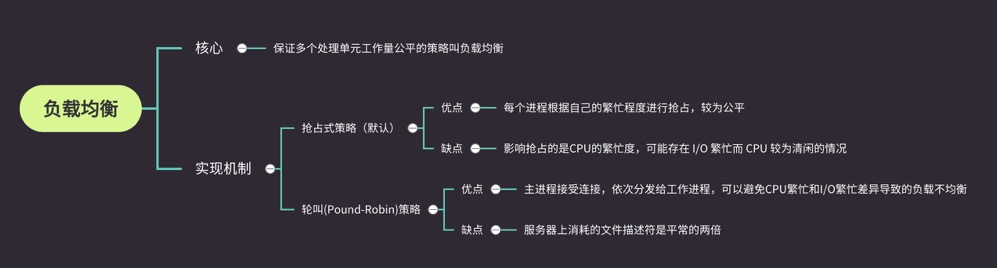
Node 进程中不宜存放过多数据,会加重垃圾回收的负担,同时 Node 也不允许在多个进程之间共享数据,解决数据共享问题最直接、简单的方式就是通过第三方来存储,比如数据库、磁盘文件、缓存服务等,所有工作进程启动时将其读取进内存中。但是这种方式还需要一种机制在数据一旦改变时通知到各个子进程使得他们的内部状态也得到更新。
实现这种同步机制的方式主要有两种:

网络编程的概念是"使用套接字来达到进程间通信的目的"。通常情况下,我们要使用网络提供的功能,可以有以下几种方式:
什么是无包构建呢?这是一个与基于模块化打包的构建方案相对的概念。
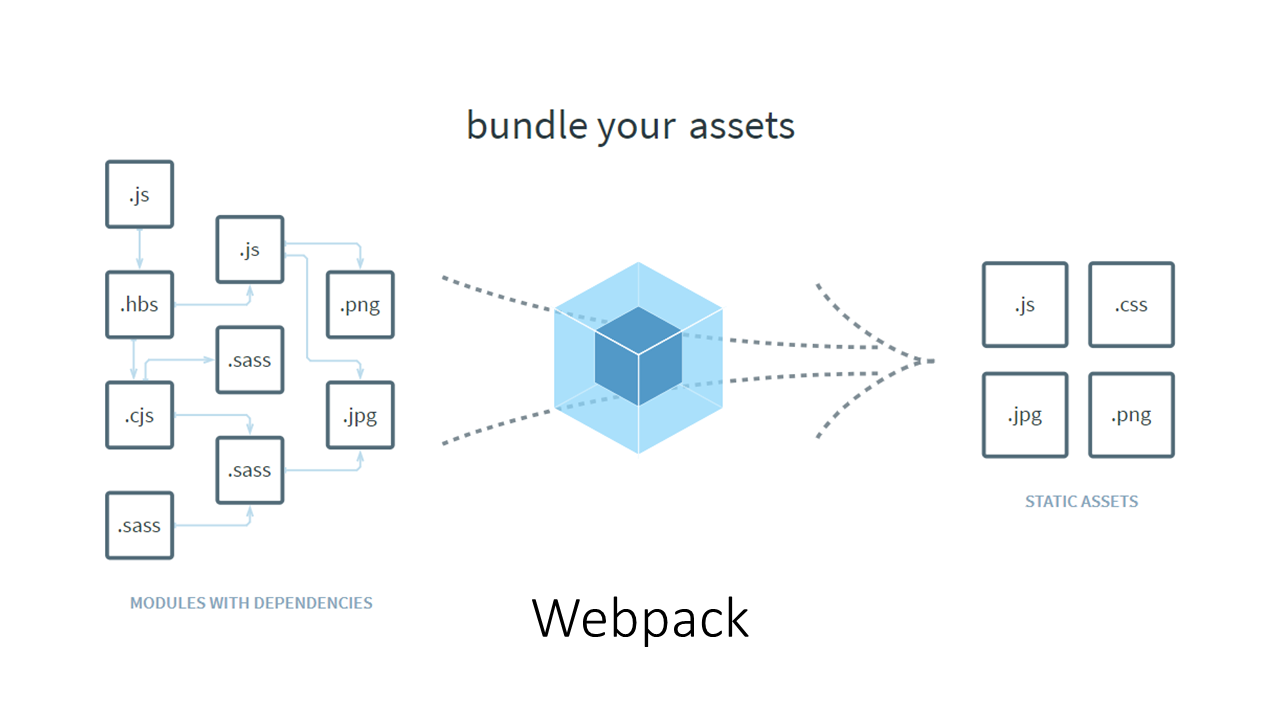
目前主流的构建工具,例如 Webpack、Rollup 等都是基于一个或多个入口点模块,通过依赖分析将有依赖关系的模块打包到一起,最后形成少数几个产物代码包,因此这些工具也被称为打包工具。只不过,这些工具的构建过程除了打包外,还包括了模块编译和代码优化等,因此称为打包式构建工具或许更恰当。
而无包构建是指这样一类构建方式:在构建时只需处理模块的编译而无须打包,把模块间的依赖关系完全交给浏览器来处理。
早些年,各大互联网公司的应用技术栈大致可分为 LAMP(Linux + Apache + MySQL + PHP)和 MVC(Spring + iBatis/Hibernate + Tomcat)两大流派。无论是 LAMP 还是 MVC,都是为单体应用架构设计的,其优点是学习成本低,开发上手快,测试、部署、运维也比较方便,甚至一个人就可以完成一个网站的开发与部署。
以 MVC 架构为例,业务通常是通过部署一个 WAR 包到 Tomcat 中,然后启动 Tomcat,监听某个端口即可对外提供服务。早期在业务规模不大、开发团队人员规模较小的时候,采用单体应用架构,团队的开发和运维成本都可控。但是单体应用架构的设计存在如下问题:
因此为了解决这些问题,服务化的思想随之而生。
Dependency Graph 概念来自官网 Dependency Graph | webpack 一文,原文解释是这样的:
Any time one file depends on another, webpack treats this as a dependency. This allows webpack to take non-code assets, such as images or web fonts, and also provide them as dependencies for your application.
When webpack processes your application, it starts from a list of modules defined on the command line or in its configuration file. Starting from these entry points, webpack recursively builds a dependency graph that includes every module your application needs, then bundles all of those modules into a small number of bundles - often, just one - to be loaded by the browser.
翻译过来核心意思是:webpack 处理应用代码时,会从开发者提供的 entry 开始递归地组建起包含所有模块的 dependency graph,之后再将这些 module 打包为 bundles 。
然而事实远不止官网描述的这么简单,Dependency Graph 贯穿 webpack 整个运行周期,从 make 阶段的模块解析,到 seal 阶段的 chunk 生成,以及 tree-shaking 功能都高度依赖于Dependency Graph ,是 webpack 资源构建的一个非常核心的数据结构
本文将围绕 webpack@v5.x 的 Dependency Graph 实现,展开讨论三个方面的内容:
在我的博客Webpack运行机制中介绍了 Webpack 的基本工作流程,并介绍了 Compiler 和 Compilation 两个核心模块中的生命周期 Hooks,那么在 Compiler 和 Compilation 的工作流程里,最耗时的阶段分别是哪个呢?
对于 Compiler 实例而言,耗时最长的显然是生成编译过程实例后的 make 阶段,在这个阶段里,会执行模块编译到优化的完整过程。而对于 Compilation 实例的工作流程来说,不同的项目和配置各有不同,但总体而言,编译模块和后续优化阶段的生成产物并压缩代码的过程都是比较耗时的。
实际上不同项目的构建,在整个流程的前期初始化阶段与最后的产物生成阶段的构建时间区别不大。真正影响整个构建效率的还是 Compilation 实例的处理过程,这一过程又可分为两个阶段:编译模块和优化处理,下面针对这两个阶段我们分别介绍对应的优化手段。
之前在微信读书零零散散看了一些章节,这次特意买了实体书认真全部看一遍,希望能用这篇博客去做一个记录和思考。
在前端开发过程中,通常我们编写的源代码会经过多重处理(编译、封装、压缩等),最后形成产物代码。于是在浏览器中调试产物代码时,我们往往会发现代码变得面目全非,因此,我们需要一种在调试时将产物代码显示回源代码的功能,SourceMap 就是实现这一目标的工具。
SourceMap 的基本原理是,在编译处理的过程中,在生成产物代码的同时生成产物代码中被转换的部分与源代码中相应部分的映射关系表。有了这样一张完整的映射表,我们就可以通过 Chrome 控制台中的"Enable Javascript source map"来实现调试时的显示与定位源代码功能。
注:我们在控制台的网络面板中通常看不到 source map 文件的请求,其原因是出于安全考虑 Chrome 隐藏了 source map 的请求,需要通过 net-log 来查询。
数组在任何一门编程语言中都是一个最常见的词,它不仅仅是一种编程语言中的数据类型,还是一种最基础的数据结构。其作为数据结构的官方定义如下所示:
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
这其中有几个关键词
vue-cli 在 3.0 版本进行了彻底的重构,为了区别也将其普遍称为 Vue CLI,是目前 Vue 官方推荐的 Vue 项目快速开发的完整系统,它基于 Webpack 实现,提供了终端命令行工具、零配置脚手架、插件体系、图形化管理界面等诸多功能,近乎提供了前端项目工程化的所有步骤的完整工具链,也是当前 Vue 项目构建的主流工具。
vue-cli 为了尽可能覆盖项目工程化需求所以模版项目往往引入了大量第三方库,但实际开发过程中开发者可能并不需要这些功能模块,虽然可以通过在模版项目的 meta.js 或 meta.json 文件配置 prompts 在命令行交互然后在 filterFiles 函数中对生成项目的文件目录结构进行筛选,但是依然可配置性不强,会存在较多冗余依赖或功能,并且依赖项的升级极为痛苦,因此为了给开发者提供更灵活的配置能力 Vue CLI 实现了一种极为巧妙的架构设计:
在 JavaScript 中数值只有一种,即 Number 类型,内部表示为双精度浮点型,即其他语言中的 double 类型,所以在 JavaScript 中实际上是没有整数类型的,数值都是按浮点数来处理的,存储方法相同,遵循 IEEE 754 国际标准,因此在 JavaScript 中 3 和 3.0 被视为同一个值,示例:
1 | 3.0 === 3 // true |
继承是面向对象语言最为重要的概念之一,许多面向对象语言都支持两种继承方式:接口继承和实现继承,接口继承只继承方法签名,而实现继承则继承实际的方法,由于JavaScript中函数没有签名,因此JavaScript中无法实现接口继承,只支持实现继承。
在传统的基于类面向对象的语言如Java、C++中,继承的本质是扩展一个已有的类,并生成新的子类。由于这类语言严格区分类和实例,继承实际上是类型的扩展。但是,JavaScript其实现继承主要是依靠原型链来实现的,本文主要介绍JavaScript中基于原型实现继承的几种主要方式:
WEB 世界出现的最初目的就是开放与共享,任何资源都可以接入其中,我们的网站可以加载并执行别人网站的脚本文件、图片、音频、视频等资源,甚至可以下载其他站点的可执行文件。但是如果这种自由没有任何限制反而会引起彻底的混乱和无序,我们的数据与隐私将被肆意窃取。随着 WEB2.0 的时代来临,互联网从C/S架构(客服端/服务端结构)转变为 B/S 架构(浏览器/服务器结构),后者相比于前者更加方便快捷,因此浏览器便成为了我们访问网站的窗口,浏览器安全也随之变得越来越重要。
浏览器安全主要可以分为Web页面安全、浏览器网络安全和浏览器系统安全,接下来我们按照这三个方面分别进行介绍:
到底什么才是前端工程化呢?我们知道一个前端项目的开发往往要经历如下步骤:
实际上在这个过程中一切以提高效率、降低成本、质量保证为目的的手段都属于前端工程化,前端工程化从早期的脚手架到现在流行的主流工具链的演变主要是因为什么呢?本篇博客希望通过对 vue-cli 和 Vue CLI 架构思想和实现分析其演变的主要原因及设计动机,也是笔者对于前端工程化的一些阶段性理解。
Grid 布局又称网格布局,是W3C提出的一个二维布局系统,它与 Flex 布局有一定的相似性,都可以指定容器内部多个项目的位置。但是,它们也存在重大区别。Flex 布局是轴线布局,只能指定"项目"针对轴线的位置,可以看作是一维布局。Grid 布局则是将容器划分成"行"和"列",产生单元格,然后指定"项目所在"的单元格,可以看作是二维布局。目前为止Grid布局是CSS中最为强大的布局方案。
从用户在浏览器中输入一个网址或关键字到浏览器成功渲染目标页面过程中到底发生了什么?浏览器端如何从远程服务器拉取目标页面?又如何完成完整页面的渲染?本篇文章将尽可能详细的展开描述这个过程。
什么是元编程?
维基百科对其的定义如下:
元编程(英语:Metaprogramming),又译超编程,是指某类计算机程序的编写,这类计算机程序编写或者操纵其它程序(或者自身)作为它们的资料,或者在运行时完成部分本应在编译时完成的工作。多数情况下,与手工编写全部代码相比,程序员可以获得更高的工作效率,或者给与程序更大的灵活度去处理新的情形而无需重新编译。
编写元程序的语言称之为元语言。被操纵的程序的语言称之为“目标语言”。一门编程语言同时也是自身的元语言的能力称之为“反射”或者“自反”。
反射是促进元编程的一种很有价值的语言特性。把编程语言自身作为一级资料类型(如LISP、Forth或Rebol)也很有用。支持泛型编程的语言也使用元编程能力。
元编程通常通过两种方式实现。一种是通过应用程序编程接口(APIs)将运行时引擎的内部信息暴露于编程代码。另一种是动态执行包含编程命令的字符串表达式。因此,“程序能够编写程序”。虽然两种方式都能用于同一种语言,但大多数语言趋向于偏向其中一种。
TypeScript 作为 JavaScript 的超集,由于其静态类型系统的引入,使得前端开发大型项目更容易实现团队内代码规范限制及接口数据约定,同时使得代码更容易阅读和理解,但是当我们在基于 TypeScript 实现大型项目的过程中同样要注意如下内容:
通过 Webpack 实现前端项目整体模块化的优势固然明显,但是它也会存在一些弊端:如果我们的应用非常复杂,这种 All in One 的打包方式就会导致打包的结果过大,然后在绝大多数情形下应用刚开始工作时并不是所有模块都是必须的,更为合理的方案是把打包的结果按照一定的规则分离到多个 bundle 中,然后根据应用的运行按需加载。这样就可以降低启动成本,提高响应速度。
其实 Webpack 官网首屏的英雄区就已经很清楚地描述了它的工作原理,如下图所示:
在 ES6 中增加了对类对象的相关定义和操作(比如class和extends),与此同时如何更加优雅地在多个不同类之间共享或者扩展一些方法或者行为也开始被提上日程,我们需要一种更优雅的方法来帮助我们完成这些事情,这个方法就是装饰器。
装饰器(decorators)这一特性的提出来源于python之类的语言,如果你熟悉python的话,对它一定不会陌生。那么我们先来看一下python里的装饰器是什么样子的吧:
A Python decorator is a function that takes another function, extending the behavior of the latter function without explicitly modifying it.
TypeScript 是一种由微软开发的自由和开源的编程语言,是 JavaScript 的一个超集,其为 JavaScript 引入了可选的静态类型,相比于 JavaScript 它的特点主要有以下三点:
那么为什么我们需要 TypeScript 帮我们引入静态类型呢?
作用域和作用域链在我学习 JavaScript 过程中曾经带给我很长时间的困惑,也曾经在CSDN总结过一篇博客,但当时好多想法在现在看来依然过于浅薄,所以想用这篇博客来梳理一下自己对于作用域和作用域链的一些全新认识和想法,也希望能帮助和我当初一样对此感到困惑的同学,知识浅薄,希望大家不吝指教。
我认为对于作用域认识的关键在于跳出 JavaScript 以一种更高的维度去看它,几乎所有编程语言最基本的功能之一就是能够储存变量当中的值,并且能够在之后对这个变量进行访问和修改,事实上正是这种储存和访问变量值的能力将状态带给了程序,因此程序语言需要制定这样一套规则来存储变量,同时能够方便在日后访问和修改这些变量,而这套规则就是作用域,我们由根据这套规则在何时生成将其分为词法作用域与动态作用域。
在详细介绍两者之前我们先需要了解编程语言的编译过程:
浮动属性最早提出是在CSS1中,其最初的主要目的就是为了允许其他内容(如文本)“围绕”图像,因此浮动属性也只允许作用于图像(有些浏览器还支持表格),后来随着不断发展,浮动属性也允许作用于任何元素,但是文本环绕这一页面样式目前仍然只有利用float属性可以实现,具有唯一性,以下面代码为例:
Flex布局又称弹性盒布局,是在CSS3中的一种新布局方式,可以简洁、方便、响应式地实现各种页面布局,因此自一提出受到了极大地追捧,目前也得到了各大主流浏览器的支持,因此迅速替代了之前的“display+float+position”的布局形式。
BFC的全称是块状格式化上下文,MDN中对于对于BFC的定义如下:
一个块格式化上下文(block formatting context) 是Web页面的可视化CSS渲染出的一部分。它是块级盒布局出现的区域,也是浮动层元素进行交互的区域。
BFC是一个独立的布局环境,按照块级盒子进行布局,其中的元素布局是不受外界的影响,并且在一个 BFC 中,块盒与行盒(行盒由一行中所有的内联元素所组成)都会垂直的沿着其父元素的边框排列。
尽管有很多关于JavaScript到底是一门面向对象还是基于对象语言的争议,但是无可否认JavaScript中对象扮演着一个举足轻重的关键角色,因此甚至有说法认为“JavaScript中万物皆对象”,当然毫无疑问这个说法是错误的,JavaScript在运行时的数据类型还包括Number、Boolean等基本类型,但是从中我们也可以感受到对象对于JavaScript中的重要意义。从语言的角度上看JavaScript中的对象更像一个字典,字符串作为键名,任意对象可以作为键值,可以通过键名读写键值。但是在V8中实现对象存储时并没有完全采取字典的存储方式,而是采用了一套更为复杂和高效的存储策略。